9. Duomenų įkėlimas ir išsaugojimas
Šiame skyriuje bus mokoma į programą „R“ įsikelti duomenis bei programoje esančius duomenis išsaugoti į duomenų bylas. Svarbiausiems duomenų formatams skirti atskiri poskyriai, kurie suskirstyti į dalis „išsaugojimas“ (aprašoma, kaip „R“ esančius duomenis išsaugoti kompiuteryje), „nuskaitymas“ (nurodoma, kaip duomenis įsikelti į programą „R“) bei „RStudio įrankiai“ (jei „RStudio“ turi įrankius, palengvinančius darbą su tam tikro tipo duomenimis, jie nagrinėjami šioje dalyje).Duomenų įkėlimo ir išsaugojimo skyriai techninėje angliškoje literatūroje gali būti trumpinami IO, I/O ar panašiai (nuo žodžių input and output), pvz., „Data IO“.
Duomenis į programą „R“ galima importuoti:
- įsikeliant iš „R“ paketų;
- nuskaitant iš duomenų bylų (esančių kompiuteryje ar internete);
- susivedant „ranka“;
- iš iškarpinės (pvz., naudojant kopijavimą, Ctrl+C), jei jie yra pateikti tinkamu formatu.
Apie įvairius (šiame skyriuje aptariamus ir neminimus) duomenų nuskaitymo aspektus galite skaityti vadovėlio „R for Data Science“ skyriuje „Data import“ , vadovėlio „YaRrr! The Pirate’s Guide to R“ skyriuje „Importing, saving and managing data“ bei funkcijų atmintinėje „Data Import“ (pirmas puslapis).
9.1 Svarbiausi duomenų bylų formatai
Priklausomai nuo prigimties, duomenys kompiuteryje, interneto svetainėse ar duomenų bazėse gali būti saugomi daugybe formatų. Šio kurso metu daugiausiai dirbsime su duomenų lentelės tipo duomenimis, todėl susipažinsime, kokiais formatais įprastai išsaugomos duomenų lentelės. Šio kurso kontekste svarbiausi bylų su duomenimis formatai pateikti pav. 9.1.
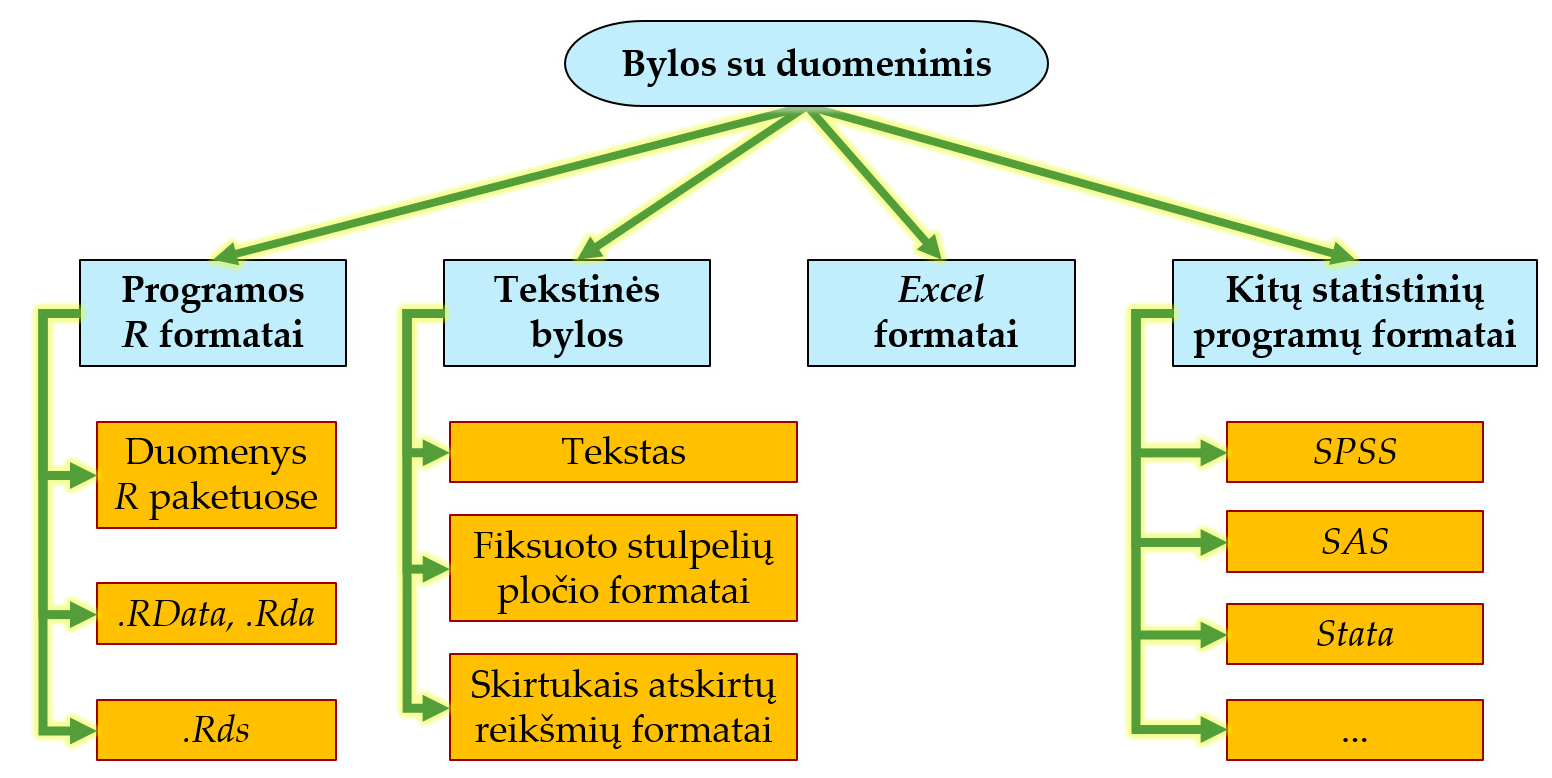
Pav. 9.1: Bylų su duomenų lentelėmis klasifikavimas. Šio kurso kontekste svarbiausi bylų su duomenimis formatai: duomenys „R“ paketuose, .Rds, .RData bylos, tekstiniai skirtukais atskirtų reikšmių formatai ir „Excel“ bylos.
Dažnai duomenų bylos tipą galime atpažinti pagal bylos pavadinimo plėtinį, pvz., .txt ar .xlsx.
Skirtingų programų ir formatų bylų pavadinimai įprastai turi standartinius tam formatui bylos pavadinimo plėtinius (taip vadinamos raidės po paskutinio taško, pagal kurias operacinė sistema parenka, kokia programa atidaryti bylą). Tam, kad juos matytumėte, rekomenduoju naudoti „RStudio“ langą „Files“, nes kitais būdais plėtiniai gali būti paslėpti (pav. 9.2). Panagrinėkime kelis šio kurso metu svarbius pavyzdžius – plėtiniai:
.txt,.csv,.datrodo, kad tai tekstiniai duomenys. Gali būti ir kitokių plėtinių arba tekstinė byla gali būti apskritai be plėtinio. Taip pat turėkite omenyje, kad tekstinėse bylose gali būti nebūtinai duomenys arba nebūtinai skirtukais atskirtų formatų duomenys, o.csvnėra „Excel“ formatas, nors ir gali turėti „Excel“ ikoną;.xlsxarba.xls– programos „Excel“ formatai;.Rds,.rds,.RDS– „R duomenų struktūros“ (Rds) formato byla;.RData,.Rda,.rda– R-data formato byla.

Pav. 9.2: Duomenų bylų pavadinimų peržiūra programomis „Windows Explorer“ (kairėje) ir „RStudio“ (dešinėje). Sistemoje „Windows“ žinomų duomenų tipų plėtiniai buvo paslėpti („Name“), bet rodomi duomenų tipų apibūdinimai („Type“). Programoje „RStudio“ plėtiniai rodomi visada. CSV (comma separated values) iš tiesų yra tekstinė byla, nors ir matoma „Excel“ ikona („rankos.csv“).
„Tidyverse“ sistemoje programos „R“ ir tekstinių duomenų formatų nuskaitymui skirtas paketas readr , „Excel“ formatams – paketas readxl , kitų statinių programų formatams – paketas haven .
9.1.1 R objektų pavadinimai
Rekomenduoju, kad kurdami „R“ objektų (šiuo atveju, nuskaitytų duomenų) pavadinimus vadovautumėtės „Tidyverse“ stiliaus gido rekomendacijomis objektų pavadinimams (nuoroda ). Ilgainiui pastebėsite, kad naudojant šias taisykles darbas su duomenimis supaprastėja, pvz., nereikia prisiminti, kuri raidė pavadinime yra didžioji, kuri – mažoji. Tema apie „R“ objektų pavadinimus plačiau nagrinėjama skyriuje „4.2.3 [Objektų pavadinimai]“. Santrauka:
- Objektų pavadinimus turi sudaryti mažosios angliškos raidės (a–z), skaičiai (0–9) ir apatiniai brūkšniai (
_); - Pavadinimas turi prasidėti raide.
9.2 R duomenų formatai
Yra trys pagrindiniai programos „R“ duomenų formatai: duomenys, pateikti „R“ paketuose, formatas .RData bei formatas .Rds (pav. 9.1).
9.2.1 Duomenys iš R paketų
Kuriant „R“ paketus, juose galima išsaugoti duomenis. Kai kurie paketai sukurti vien tik duomenų saugojimui.
Išsaugojimas
Būdai, kaip į paketą įrašyti duomenis įprastai nagrinėjami einant temas apie „R“ paketų kūrimą (pvz., vadovėlyje „R packages“ ). Šiame skyriuje to nenagrinėsime.
Nuskaitymas
Labai naudinga mokėti įsikelti „R“ paketuose esančius duomenis. Įprastai tokie duomenys skirti įvairių analizių ir metodų išbandymui. Šiuo tikslu naudojama funkcija data(), kurios skliaustuose nurodomas duomenų lentelės pavadinimas ir paketo pavadinimas, pvz.:
arba
Jei paketas yra užkrautas, argumento package galite ir nenaudoti. Visgi dėl aiškumo rekomenduoju nurodyti ir paketą.
Pradžioje duomenys gali būti įkrauti tik iš dalies rezervuojant pavadinimą, bet pačių duomenų į kompiuterio atmintį neįkeliant. Tokiu atveju galite matyti užrašą <Promise> (pav., 9.3). Duomenys galutinai įkeliami tik atlikus kokį nors veiksmą su jais. Tai vienas iš tingiojo užkrovimo (angl. lazy loading) pavyzdžių.
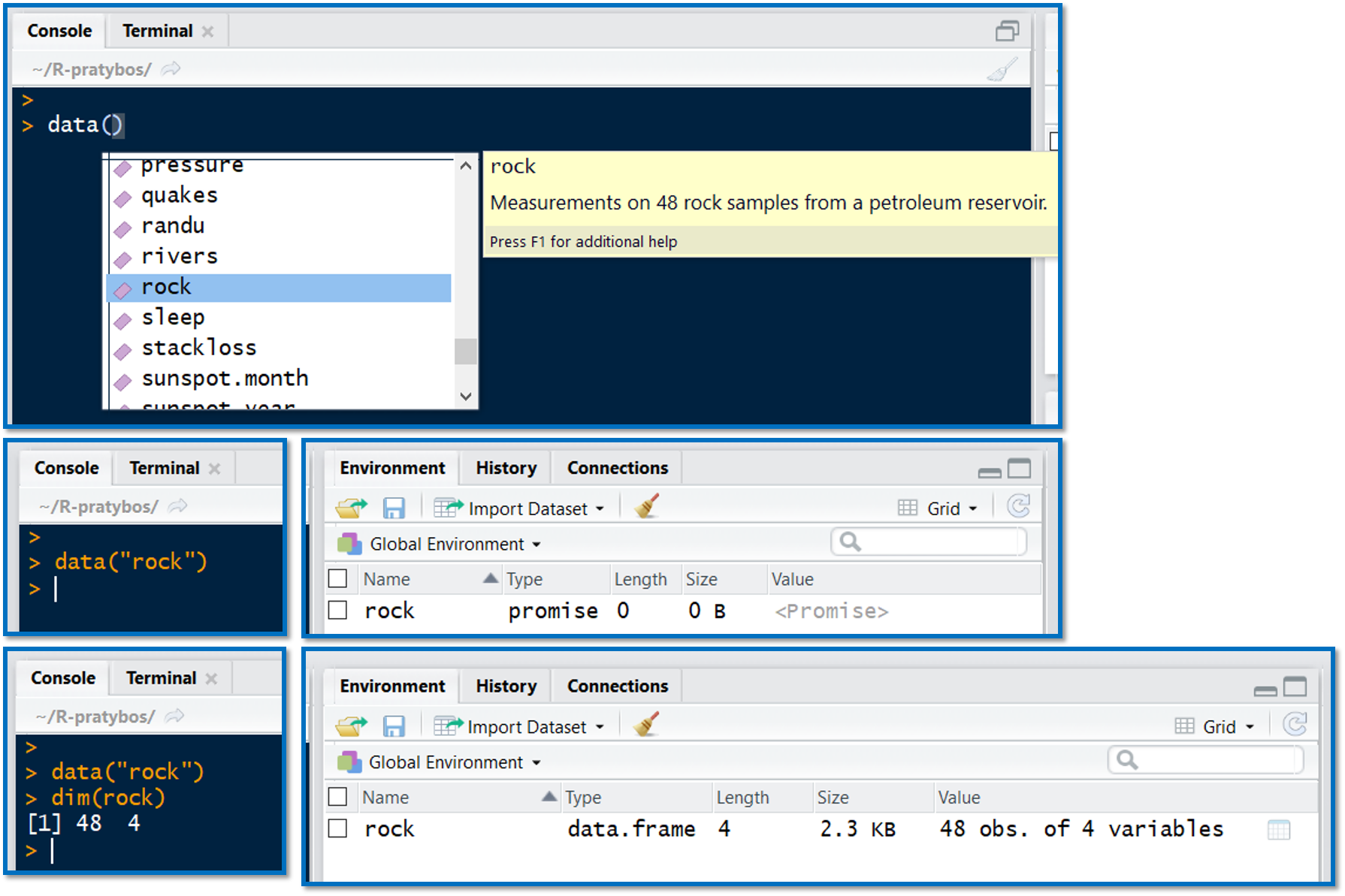
Pav. 9.3: Duomenų iš „R“ paketų užkrovimas. Šio tipo duomenys užkraunami naudojant komandą data(). Vos parašius šią komandą, „RStudio“ ima siūlyti galimus duomenų rinkinių pavadinimus, kuriuos galima pasirinkti pele. Funkcija data() įprastai įvykdo tik pirminį įkėlimą ir rezervuoja pavadinimą „R“ atmintyje, todėl matome užrašą „promise“. Galutinis įkėlimas į „R“ atmintį įvyksta, kai su duomenimis atliekame kokį nors veiksmą, pavyzdžiui, panaudoję funkciją dim() nustatome duomenų lentelės eilučių ir stulpelių skaičių.
Dėstydamas ankstesniais metais pastebėjau, kad naudodami šio poskyrio medžiagą studentai bando nuskaityti bet kokius duomenis. Visgi įsiminkite, kad:
Funkcija data() skirta nuskaityti ne bet kokius, o tik mokomuosius duomenis iš „R“ paketų.
9.2.2 .RData formatas
„RData“ yra programos „R“ duomenų formatas, kuriuo galima išsaugoti vieną ar net visus programos „R“ darbinėje erdvėje esančius objektus. Šiuo formatu automatiškai išsaugomi objektai, kai išjungiama programa „R“ (jei toks išsaugojimas nėra išjungtas). Formatu .RData galima išsaugoti tiek duomenų lenteles, tiek kokios klasės objektus. Išsaugojimui ir nuskaitymui naudojamos paketo base funkcijos. Užkraunant objektą, išlieka visos programoje „R“ nustatytos objektų savybės, pvz., kategorinių kintamųjų kategorijų eilės tvarka. Užkraunant duomenis iš .RData formato bylos negalima pakeisti objektų pavadinimų – lieka tokie, kokius išsaugojome.
Jei „R“ atmintyje yra objektas (žiūrėti „RStudio“ lange „Environment“) tokiu pat pavadinimu, kaip ir „.RData“ byloje (įprastai kol neėsikeliame, pažiūrėti negalime), tai atidarius šią bylą senasis objektas iš atminties bus ištrintas ir pakeistas naujuoju, kuris buvo nuskaitytoje byloje. Būkite atidūs, kad neprarastumėte svarbių duomenų.
Būtent dėl šios priežasties iš visų „R“ duomenų formatų .RData rekomenduoju mažiausiai.
Išsaugojimas
Jei norime išsaugoti vieną ar kelis objektus .RData formatu, naudojame funkciją save() ir nurodome jų pavadinimus bei bylos pavadinimą, kurios plėtinys turėtų būti .RData.
Jei norime išsaugoti visus darbinėje erdvėje esančius objektus, naudojame funkciją save.image() ir nurodome tik bylos pavadinimą, kurios plėtinys turėtų būti .RData.
Nuskaitymas
Šio formato duomenų nuskaitymui naudojama funkcija load(). Jai nurodomas tik nuskaitomos bylos pavadinimas. Duomenų objektams, esantiems .RData byloje, pavadinimų suteikti negalime.
RStudio įrankiai
„RStudio“ įrankiai, skirti .RData formato duomenų nuskaitymui vaizduojami pav. 9.4 ir demonstruojami video epizode 9.2.
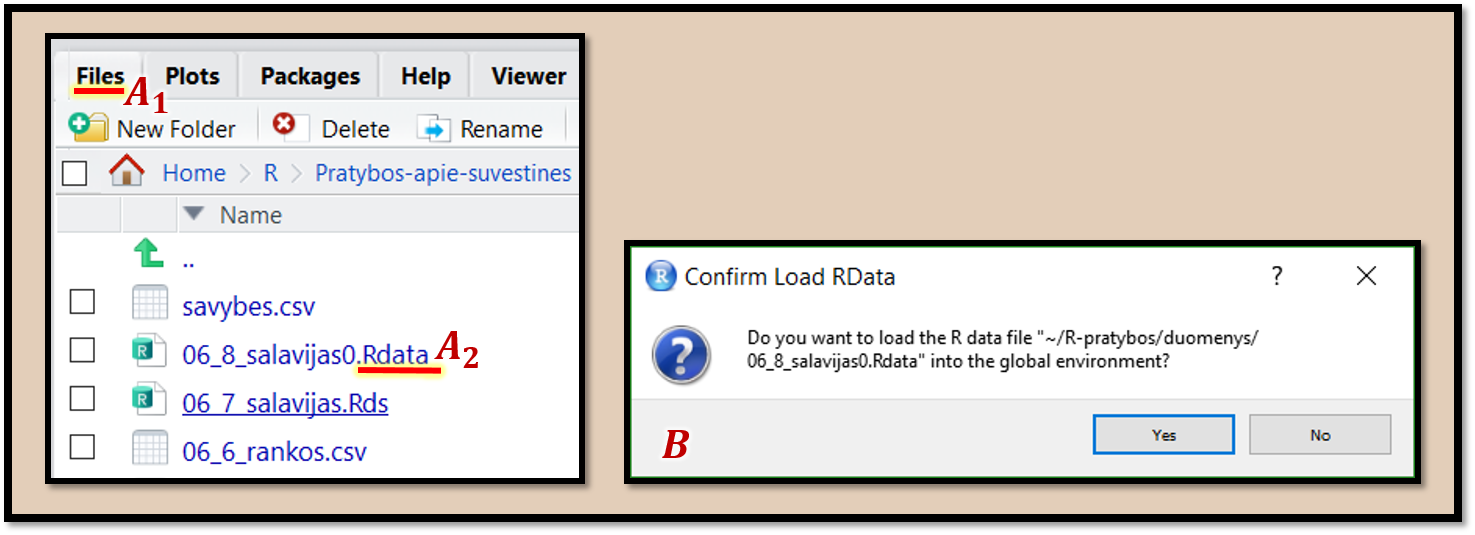
Pav. 9.4: Programos „R“ „.Rdata“ formato duomenų nuskaitymas Bylų plėtinys gali būti .Rda, .RData, .Rdata ar analogiškas.
Panagrinėkime pav. 9.4. Kortelėje „Files“ \((A_1)\) atsidarome aplanką su duomenimis. Pele spustelime .RData formato bylos pavadinimą \((A_2)\). Atsidaro langas \((B)\), kuriame klausiama, ar tikrai norime įsikelti duomenis, ir kad jei byloje bus objektas tokiu pat pavadinimu, kaip „R“ atmintyje, pastarasis bus prarastas. Jei sutinkame, spaudžiame „Yes“. „R“ konsolėje parašomas duomenų nuskaitymo kodas (demonstruojama video epizode 9.2). Jei reikia, jį galime nusikopijuoti ir įklijuoti į duomenų analizei skirtą bylą.
9.2.3 .Rds formatas
Formatu .Rds galime išsaugoti bet kokį „R“ darbinėje erdvėje esantį objektą. Tačiau tik vieną. Užkraunant išsaugomos visos anksčiau nustatytos objekto savybės, tačiau reikia sukurti naują pavadinimą. Dėl pastarosios priežasties formatas yra saugesnis už .RData.
Šį „R“ duomenų formatą rekomenduoju labiausiai.
Išsaugojimas
Išsaugojimui .Rds formatu galime naudoti readr („Tidyverse“ šeimos paketas) funkciją write_rds(). Išsaugomos bylos plėtinys turi būti .rds arba .Rds.
Šiam tikslui skirta ir bazinės sistemos funkcija saveRDS().
Nuskaitymas
.Rds formato nuskaitymui naudojama readr funkcija read_rds().
Arba bazinės sistemos readRDS().
RStudio įrankiai
„RStudio“ turi įrankius, palengvinančius .rds formato duomenų nuskaitymą. Panagrinėkime pav. 9.5 pateiktą medžiagą. Kortelėje „Files“ \((A_1)\) atsidarome aplanką su duomenimis. Pele spustelime .rds formato bylos pavadinimą \((A_2)\). Atsidaro langas \((B)\), kuriame parašome kokiu pavadinimu „R“ vadinsis nuskaitytas objektas \((B_1)\), ir paspaudžiame „OK“ mygtuką \((B_2)\). „R“ konsolėje parašomas duomenų nuskaitymo kodas (demonstruojama video epizode 9.2). Jį nusikopijuojame ir įklijuojame į duomenų analizei skirtą bylą.
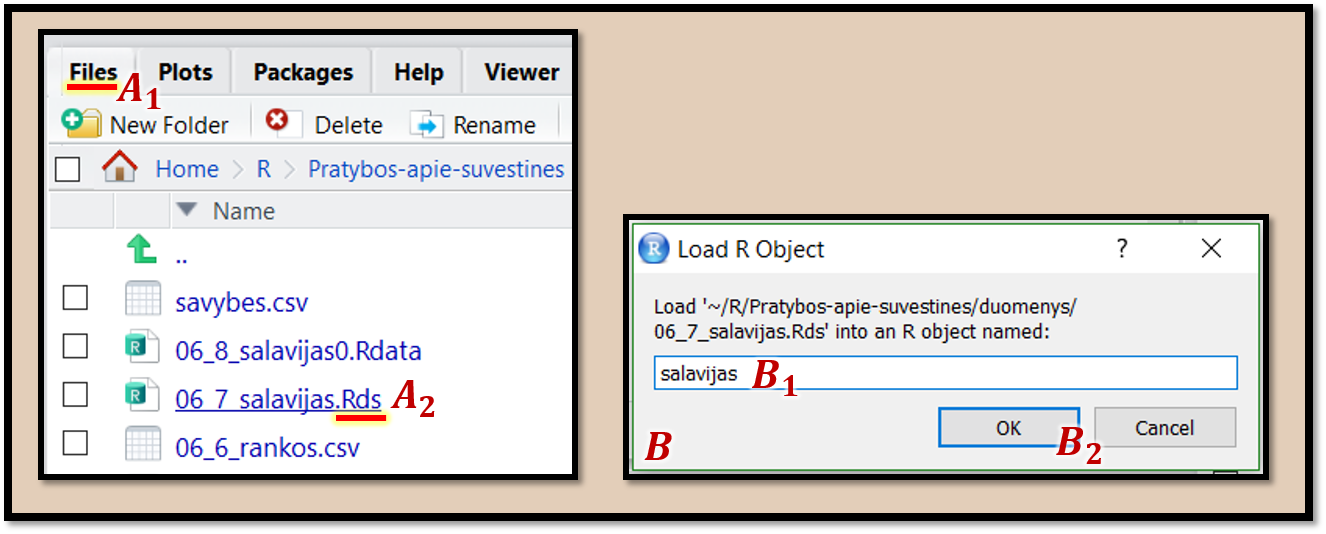
Pav. 9.5: Programos „R“ „.Rds“ formato duomenų nuskaitymas naudojant „RStudio“. Bylų plėtinys gali būti .Rds, .RDS, .rds ar analogiškas.
9.3 Excel duomenų formatai
Yra du programos „Excel“ bylų formatai – senesnis .xls ir naujesnis .xlsx. Programa „R“ galima nuskaityti duomenis iš abiejų formatų.
Išsaugojimas
„Tidyverse“ kol kas neturi oficialaus paketo duomenų įrašymui į „Excel“ bylas. Paketai, kurie gali būti naudojami šiuo tikslu: openxlsx, xlsx (paketui reikia „Java“), writexl.
Paprastas pavyzdys naudojant paketą openxlsx.
Sudėtingesnis pavyzdys naudojant paketą openxlsx: parenkamas lapo pavadinimas, kortelės spalva, stulpelių pločiai, o stulpelių pavadinimai pajuodinami.
openxlsx::write.xlsx(
duomenys,
file = "byla.xlsx",
sheetName = "lapas_3",
tabColour = "red",
colWidths = "auto",
headerStyle = openxlsx::createStyle(textDecoration = "BOLD"),
overwrite = FALSE
)Daugiau pavyzdžių galite rasti paketo vinjetėse („Introduction“ , „Formatting Examples“ ).
Nuskaitymas
Oficialus „Tidyverse“ paketas Excel byloms nuskaityti yra readxl .
Įprastinė darbo eiga: užsikrauti paketą, pasirinkti bylą su duomenimis ir nustatyti, kuriame bylos lape yra reikalingi duomenys, duomenis iš šio lapo (nurodant arba lapo pavadinimą, arba numerį) nuskaityti. Programiškai tai atrodytų šitaip:
library(readxl)
excel_sheets("byla.xlsx")
duomenys <- read_excel("byla.xlsx", sheet = "lapo_pavadinimas") # arba
duomenys <- read_excel("byla.xlsx", sheet = 1)Svarbiausi funkcijos read_excel() argumentai:
path– (tekstas) bylos pavadinimas (su aplanko pavadinimu);sheet– (tekstas arba sveikasis skaičius) lapo pavadinimas arba numeris;skip– (sveikasis skaičius) mažiausias viršutinių eilučių skaičius, kurį programa praleis prieš nuskaitydama duomenis;n_max(sveikasis skaičius) – didžiausias eilučių skaičius, kurį programa nuskaitys;col_names– (loginė reikšmė arba tekstas) jeiTRUE, pirma nuskaityta eilutė laikoma stulpelių pavadinimais; jeiFALSE– pavadinimai sukuriami automatiškai; arba nurodomi kiekvieno stulpelio pavadinimai.na– (tekstas) simboliai, kurie bus laikomi praleistomis reikšmėmis.range– (tekstas) Excel langelių sritis, kurią norima nuskaityti, pvz.,"B3:D87"arba"Lapas1!B2:G14".
Daugiau skaitykite funkcijos dokumentacijoje ?readxl::read_excel.
Užduotis 9.2
- Parsisiųskite „Excel“ bylą „azotas-fosfatas-kalis.xlsx“ ir išsaugokite aktyviajame programos „R“ aplanke.
- Nuskaitykite bylos duomenis į „RStudio“.
- Koks kintamojo yield reikšmių vidurkis?
RStudio įrankiai
„RStudio“ įrankiai, skirti nuskaityti duomenis iš „Excel“ bylų, vaizduojami video epizoduose 9.3 ir 9.4.
Užduotis 9.2
- Parsisiųskite šią Excel bylą: https://mokymai.github.io/pratybos/duomenys/azotas-fosfatas-kalis.xlsx ir išsaugokite aktyviajame programos „R“ aplanke.
- Nuskaitykite bylos duomenis į „RStudio“.
- Koks kintamojo
yieldreikšmių vidurkis?
# Pavyzdys: nubraižome duomenų lentelės „Orange“
# stulpelius „age“ ir „circumference“
with(Orange, plot(x = age, y = circumference, col = "blue"))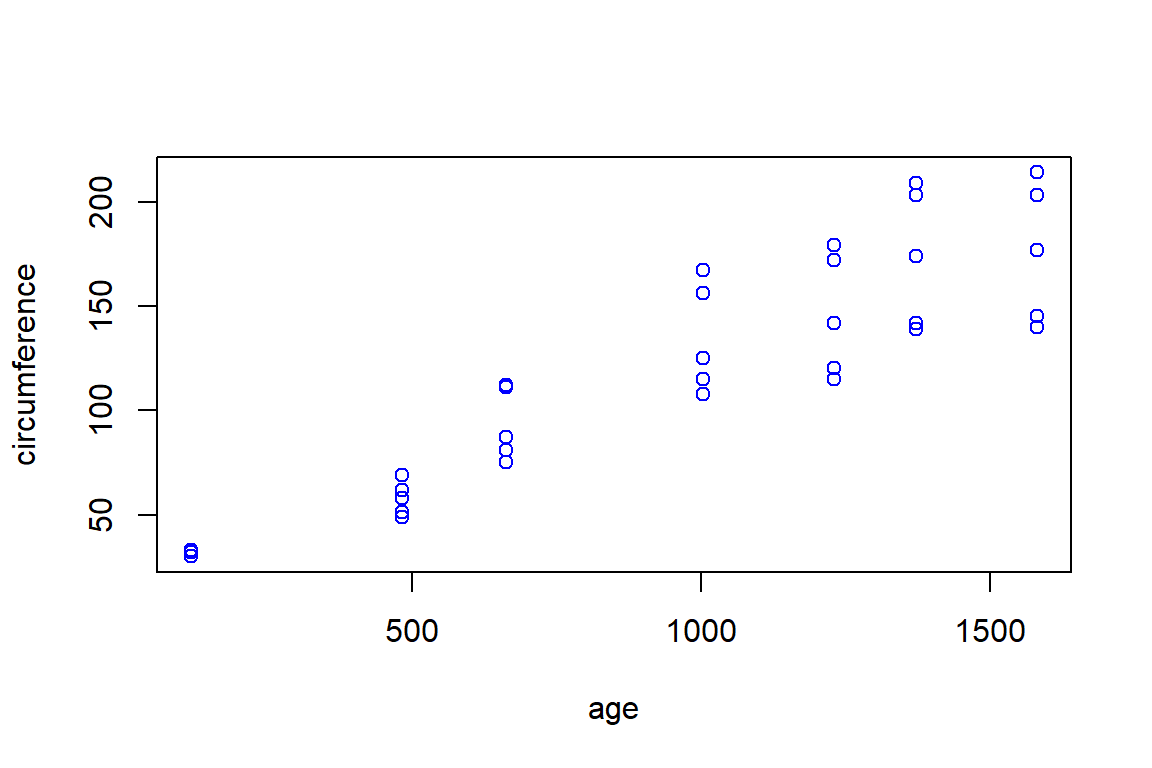
Pav. 9.6: Pavyzdys, kaip turėtų atrodyti aukščiau pateiktos užduoties atsakymas.
9.4 Teksto eilutės
Tekstinėse bylose duomenys gali būti išsaugoti keliomis formomis (pav. 9.1). Tokiose bylose gali būti nestruktūruoti duomenys arba tiesiog tekstas, kurį galima nuskaityti kaip teksto eilutes, arba duomenų lentelės (struktūruoti duomenys), išsaugoti arba skirtukais atskirtų reikšmių, arba fiksuoto pločio stulpelių formatais. Tekstinės bylos įprastai būna pažymėtos plėtiniais .txt, .csv arba .dat. Gali būti ir kitokių arba byla gali apskritai būti be plėtinio, bet šie trys yra dažniausi.
Byla plėtiniu .csv yra tekstinė, o ne „Excel“ formato byla, nors jos ikona gali būti panaši į „Excel“ bylos.
Šiame skyriuje bus aptariama, kaip nuskaityti teksto eilutes.
Išsaugojimas
Teksto eilučių išsaugojimui įprastai naudojama paketo readr funkcija write_lines(). Svarbiausi jos argumentai:
x– tai duomenų objektas, kurį įrašome;path– (tekstas) bylos, į kurią įrašome, pavadinimas;append– loginė reikšmė, nurodanti, ar pridėti naujas eilutes, jei byla jau egzistuoja (append = TRUE), ar ištrinti jau esančius duomenis iš bylos ir įrašyti tik naujuosius (append = FALSE).
Daugiau apie funkciją – dokumentacijoje (?readr::write_lines).
Baziniame „R“ pakete yra analogiškiems tikslams skirta funkcija writeLines(). Kartais gali būti naudinga ir readr::write_file() funkcija.
Nuskaitymas
Teksto eilučių nuskaitymui naudojamos „Tidyverse“ šeimos paketo readr funkcijos:
read_lines()– kiekvieną eilutę nuskaito kaip atskirą eilutę, t. y., kaip atskirą „R“ vektoriaus elementą;read_file()– visą bylos turinį nuskaito kaip vieną eilutę.
Svarbiausi teksto eilutes nuskaitančių „Tidyverse“ funkcijų argumentai:
file– (tekstas) bylos pavadinimas (su aplanko pavadinimu), internete esančių duomenų adresas arba tiesiog duomenys (tekstas);skip– (sveikasis skaičius) viršutinių eilučių skaičius, kurį programa praleis prieš nuskaitydama duomenis/tekstą;n_max(sveikasis skaičius) – didžiausias eilučių skaičius, kurį programa nuskaitys. Kain_max = -1, bus nuskaitomos visos eilutės;na– (tekstas) simboliai, kurie bus laikomi praleistomis reikšmėmis.locale– (objektas, sukurtas funkcijalocale()) tai nuo kalbos ir vietovės priklausantys nustatymai. Pavyzdžių ieškokite dokumentacijoje;progress– (loginė reikšmė) nurodoma, ar rodyti progreso juostą esant didelei bylai.
9.5 Skirtukais atskirtų reikšmių (SAR) formatas
Tekstinėse bylose duomenų lentelės gali būti išsaugotos keliomis formomis. Šiame skyriuje aptarsime tekstinį skirtukais atskirtų reikšmių (trumpinsime SAR) formatą. Nagrinėjant šio skyriaus medžiagą, gali būti naudinga atmintinė Data Import Cheat Sheet. Esminiai dalykai, kuriuos reikia pastebėti prieš nuskaitant duomenis, išsaugotus šiuo formatu:
- Sveikosios ir dešimtosios skaičiaus dalies skirtukas (angl., decimal separator). Juo gali būti arba taškas (
., angl. period, jei tai angliškas/amerikietiškas užrašymo variantas), arba kablelis (,, angl. comma, jei tai europietiškas/lietuviškasis variantas); - Stulpelių (reikšmių) skirtukas (angl., field separator, delimiter). Juo gali būti kablelis, kabliataškis (angl., semicolon), tarpas, tabuliacija („ilgas tarpas“), vertikalus brūkšnys (
|) ar kitoks simbolis, bet ne taškas (.).
Vienas iš dažniausių tekstinių duomenų formatų – .csv (angl. comma sepatated values). Šios rūšies formatai būna 2 tipų:
- csv 1 („amerikietiškasis“) formatas, kuriame sveikosios ir dešimtosios skaičiaus dalių skirtukas yra taškas (
.), o stulpelių skirtukas yra kablelis (,). - csv 2 („europietiškasis“) formatas, kuriame sveikosios ir dešimtosios dalių skirtukas – kablelis (
,), o stulpelių skirtukas – kabliataškis (;).
Jei skaičiai į programą „R“ nuskaityti teisingai, tai programoje „R“ tarp sveikosios ir dešimtosios dalies privalo būti taškas, o ne kablelis, pvz., 22.6.
Tekstinių bylų pavyzdžiai pateikti pav. 9.7.
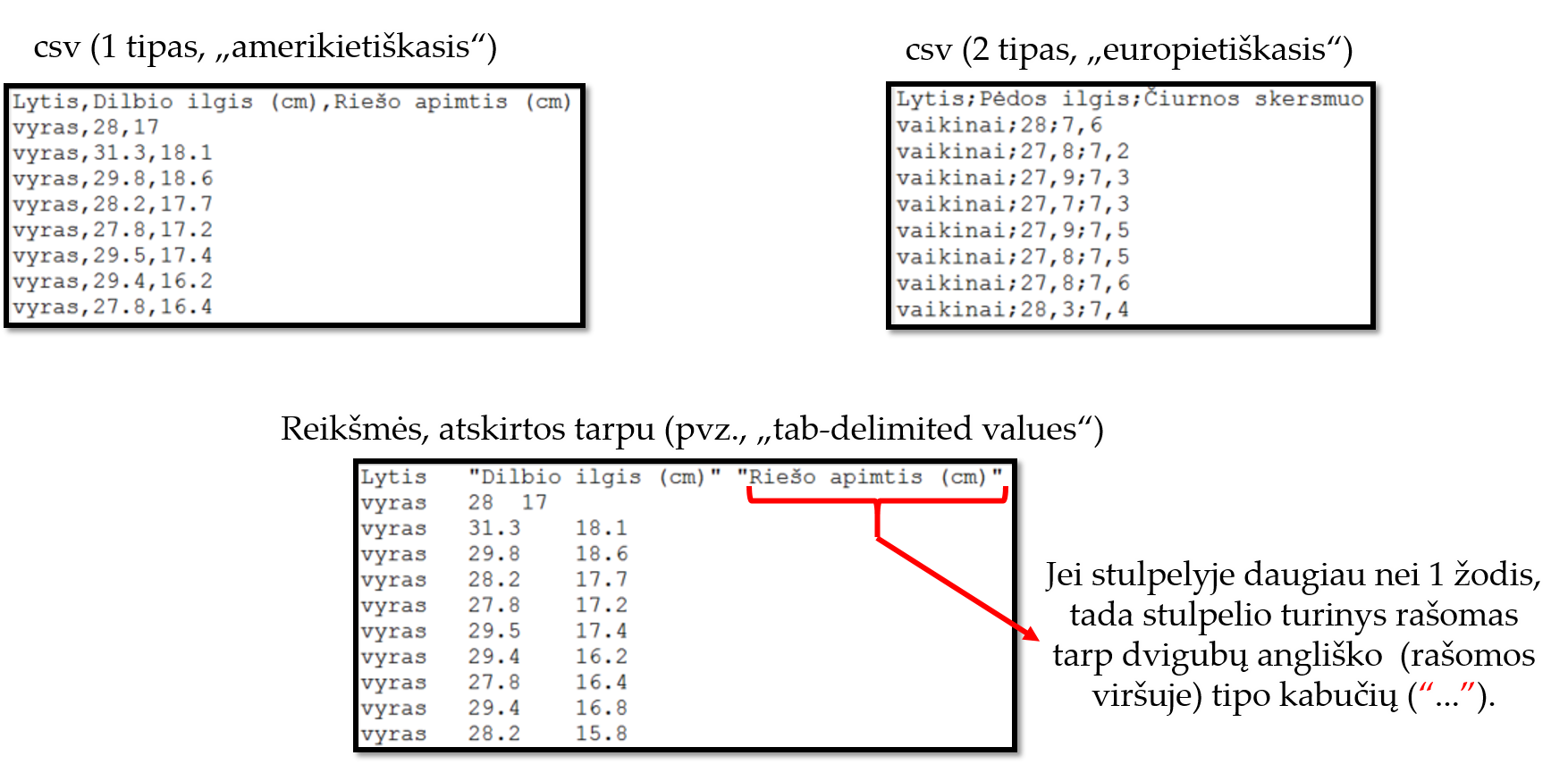
Pav. 9.7: Tekstinėse bylose skirtukais atskirtų reikšmių formatu saugomų duomenų pavyzdžiai.
Įprastai duomenų stulpelių pavadinimai būna pirmoje eilutėje, o kiekviena kita eilutė yra skirta duomenims. Sakykime, kad tai įprastinis duomenų pateikimo budas. Pvz.:
pavadinimas_1;pavadinimas_2;pavadinimas_3
1,0;A;vyras
6,1;A;moteris
5,2;B;vyrasTačiau gali būti, kad virš duomenų yra komentarai:
Tai komentaras apie duomenis, o ne patys duomenys
pavadinimas_1;pavadinimas_2;pavadinimas_3
1,0;A;vyras
6,1;A;moteris
5,2;B;vyrasKomentarai gali būti pažymėti kokiu nors simboliu:
# Tai komentaras apie duomenis
pavadinimas_1;pavadinimas_2;pavadinimas_3
1,0;A;vyras
6,1;A;moteris
5,2;B;vyrasTaip pat gali nebūti stulpelių pavadinimų:
1,0;A;vyras
6,1;A;moteris
5,2;B;vyrasGali būti skirtingu būdu užrašomų praleistų reikšmių. Pvz., praleista reikšmė pažymėta NA:
# NA - praleista reikšmė
pavadinimas_1;pavadinimas_2;pavadinimas_3
NA;A;vyras
6,1;A;NA
5,2;B;vyrasPraleista reikšmė pažymėta ?:
pavadinimas_1;pavadinimas_2;pavadinimas_3
?;A;vyras
6,1;A;?
5,2;B;vyrasPraleistos reikšmės turi skirtingus žymėjimus:
pavadinimas_1;pavadinimas_2;pavadinimas_3
NA;A;vyras
6,1;A;?
5,2;B;vyrasJei duomenyse yra neangliškų raidžių ar kitokių neįprastų simbolių, gali reikti pasirinkti tinkamą koduotę, tarkime UTF-8. Taip pat dirbant su lietuviškais simboliais turėtų būti nustatyta lietuviškoji lokalė tiek programoje „R“, tiek operacinėje sistemoje (Windows/MAC/Linux), nes kitaip gali kilti nesklandumų.
Tad nuskaitydami duomenis būkite atidūs ir pasirinkite tinkamus nuskaitymo parametrus.
Norintys gilesnių žinių apie CSV bylų sudarymo taisykles gali peržiūrėti šį šaltinį .
9.5.1 Tidyverse sistemos funkcijos SAR duomenų formatams
Išsaugojimas
Duomenų lentelių išsaugojimui naudojamos „Tidyverse“ funkcijos, prasidedančios write_:
write_delim()– išsaugojimas skirtukais atskirtų reikšmių formatu. Skirtuką galima pasirinkit, nepasirinkus naudojamas tarpas;write_tsv()– išsaugojimas reikšmes atskiriant tabuliacijomis;write_csv()– išsaugojimas CSV 1 tipo formatu;write_excel_csv()– išsaugojimas CSV 1 tipo formatu, kuriame yra žyma , dėl kurios byla tampa labiau pritaikyta atidaryti programa „Excel“.
write_delim(x = duomenys, path = "byla1.txt")
write_tsv(x = duomenys, path = "byla2.txt")
write_csv(x = duomenys, path = "byla3.csv")
write_excel_csv(x = duomenys, path = "byla4.csv")Alternatyva „Tidyverse“ funkcijoms – bazinės „R“ funkcijos write.table(), write.csv(), write.csv2() arba paketo data.table funkcija fwrite().
Nuskaitymas
SAR formatų bylų nuskaitymui naudojamos „Tidyverse“ funkcijos, prasidedančios read_.
read_delim()– skirta nuskaityti SAR formatų bylas nurodant reikšmių (stulpelių) skirtuką;read_tsv()– tairead_delim()variantas, kai reikšmių skirtumas yra tabuliacija;read_csv()– skirta CSV 1 tipo byloms nuskaityti;read_csv2()– skirta CSV 2 tipo byloms nuskaityti;read_table()– skirta nuskaityti SAR formatų bylas, kai reikšmių skirtukais yra vienas arba keli tarpai. Dokumento eilučių struktūra yra griežta, vizualiai primena lentelę ir galima teigti, kad tai atskiras fiksuoto pločio stulpelių formato variantas (aprašomas skyriuje 9.6): kiekviena eilutė privalo būti vienodo ilgio, o kiekvienas stulpelis – toje pačioje pozicijoje.read_table2()– skirta nuskaityti SAR formatų bylas, kai reikšmių skirtukais yra vienas arba keli tarpai. Eilutės gali būti skirtingo ilgio, o tarp reikšmių esantis tarpų skaičius gali kisti.
duomenys <- read_delim(file = "byla.txt")
duomenys <- read_tsv(file = "byla.txt")
duomenys <- read_csv(file = "byla.txt")
duomenys <- read_csv2(file = "byla.txt")
duomenys <- read_table(file = "byla.txt")
duomenys <- read_table2(file = "byla.txt")Svarbiausi tekstinius SAR formato duomenis nuskaitančių „Tidyverse“ funkcijų argumentai:
file– (tekstas) bylos pavadinimas (su aplanko pavadinimu), internete esančių duomenų adresas arba tiesiog duomenys (tekstas);delim– (tekstas) duomenų reikšmių (stulpelių) skirtumas;locale– (objektas, sukurtas funkcijalocale()) tai nuo kalbos ir vietovės priklausantys nustatymai; Pvz., jei sveikosios ir dešimtosios dalies skirtukas yra kablelis, o ne taškas, reikia nurodyti:locale = locale(decimal_mark = ",");skip– (sveikasis skaičius) viršutinių eilučių skaičius, kurį programa praleis prieš nuskaitydama duomenis/tekstą;n_max(sveikasis skaičius) – didžiausias eilučių skaičius, kurį programa nuskaitys;na– (tekstas) simboliai, kurie bus laikomi praleistomis reikšmėmis;col_names– (loginė reikšmė arba tekstas) jeiTRUE, pirma nuskaityta eilutė laikoma stulpelių pavadinimais; jeiFALSE– pavadinimai sukuriami automatiškai; arba nurodomi kiekvieno stulpelio pavadinimai;comment– (tekstas) komentaro simbolis, po kurio eilutėje esantis tekstas nebus nuskaitomas;progress– (loginė reikšmė) nurodoma, ar rodyti progreso juostą esant didelei bylai.
Kaip alternatyva „Tidyverse“ funkcijoms gali būti naudojamos bazinės „R“ funkcijos read.csv(), read.csv2(), read.table(), read.delim(), read.delim2() arba data.table paketo funkcija fread() (skyrius „9.5.2 Funkcija fread()“).
RStudio įrankiai
„RStudio“ įrankiai, duomenims nuskaityti naudojantys „Tidyverse“ funkcijas, demonstruojami video epizoduose 9.5 ir 9.6. Įrankiai, naudojantys bazinės sistemos funkcijas, demonstruojami pav. 9.9 ir video epizode 9.7.
(„Tidyverse“ sistemos funkcijos – pirma dalis). Demonstruojami duomenys .
Užduotis 9.4
- „RStudio“ projekte „Pratybos_2_darbui_auditorijoje“, kurį atsisiuntėte darydami 6.11 skyriaus užduotis, yra aplankas „duomenys“. Jame yra 2 .csv bylos. Teisingai nuskaitykite duomenis, esančius abejose bylose.
Norintiems gilesnių žinių apie CSV bylų sudarymo taisykles gali pagelbėti ši nuoroda: https://en.wikipedia.org/wiki/Comma-separated_values#Basic_rules
(„Tidyverse“ sistemos funkcijos – antra dalis). Demonstruojami duomenys .
Dėmesio: dirbant „RStudio“ ir naudojant „Tidyverse“ duomenų nuskaitymo meniu gali kilti problemų nuskaitant tekstinius duomenis, kai stulpelių skirtukai yra keli tarpai. Problemą išspręsite vietoje komandos read_table() naudodami read_table2().
Užduotis 9.5
- Atsidarykite aplanką „duomenys-2“, esantį to paties „RStudio“ projekto „Pratybos_2_darbui_auditorijoje“ aplanke. Teisingai nuskaitykite duomenis, esančius 7-iose bylose, kurių pradžia „01_“, o plėtinys „.txt“.
- Atsidarykite aplanką „duomenys“, esantį to paties projekto aplanke.
- Teisingai nuskaitykite duomenis, esančius visose tekstinėse bylose, kurių plėtinys „.txt“ arba „.dat“. (Tie patys duomenys pateikti keliais formatais, jei nuskaitėte teisingai – atitinkamų duomenų lentelės turi būti identiškos).
Norėdami nuskaitydami tekstinio formato duomenis galite naudoti ir „RStudio“ įrankį „From Text (base)“ (pav. 9.8, 9.9, video epizodas 9.7). Daugelis nuskaitymo parametrų įprastai teisingai parenkami automatiškai. Tačiau kiekvieną kartą įsitikinkite, ar tikrai stulpeliai turi teisingus pavadinimus (juos vaizduoja pirmoji, pajuodinta, eilutė lange „Data Frame“) ir kiekvienas stulpelis nuskaitomas kaip atskiras stulpelis. Jei duomenyse yra lietuviškų ar kitokių ne angliškų simbolių, gali reikti pasirinkti UTF-8 koduotę.
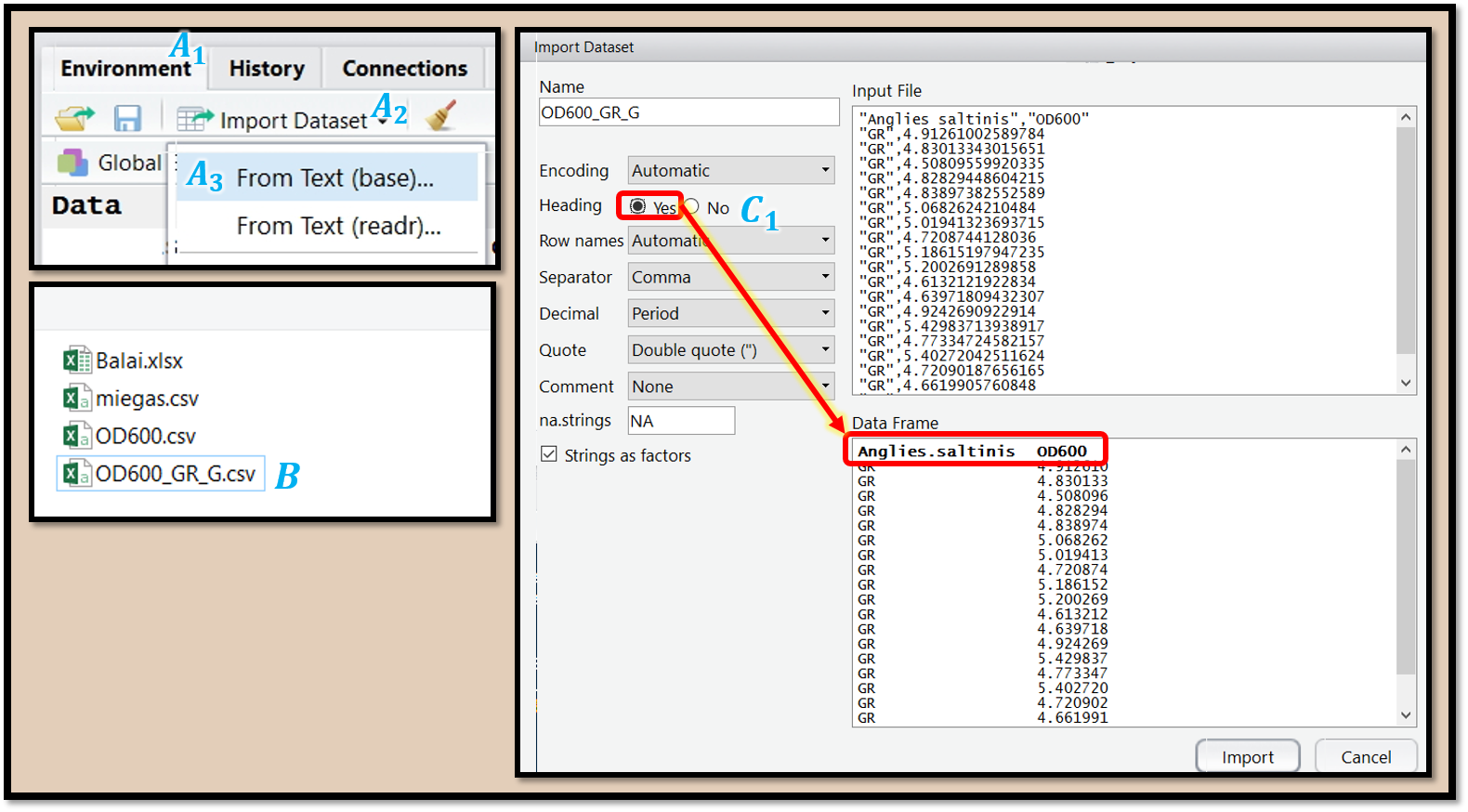
Pav. 9.8: Duomenų nuskaitymas. \(A_1\), \(A_2\), \(A_3\) – tekstinių duomenų nuskaitymo meniu atidarymas. \(B\) – norimos tekstinių duomenų bylos pasirinkimas. Tam, kad pirma duomenų eilutė būtų nuskaityta kaip pavadinimai, ties užrašu „Heading“ turi būti pasirinkta „Yes“ (\(C_1\)). Įsikėlus duomenis, duomenų nuskaitymo programos kodas pasirodo lange „Console“ (pav. 9.10).
(Bazinės „R“ sistemos funkcijos).
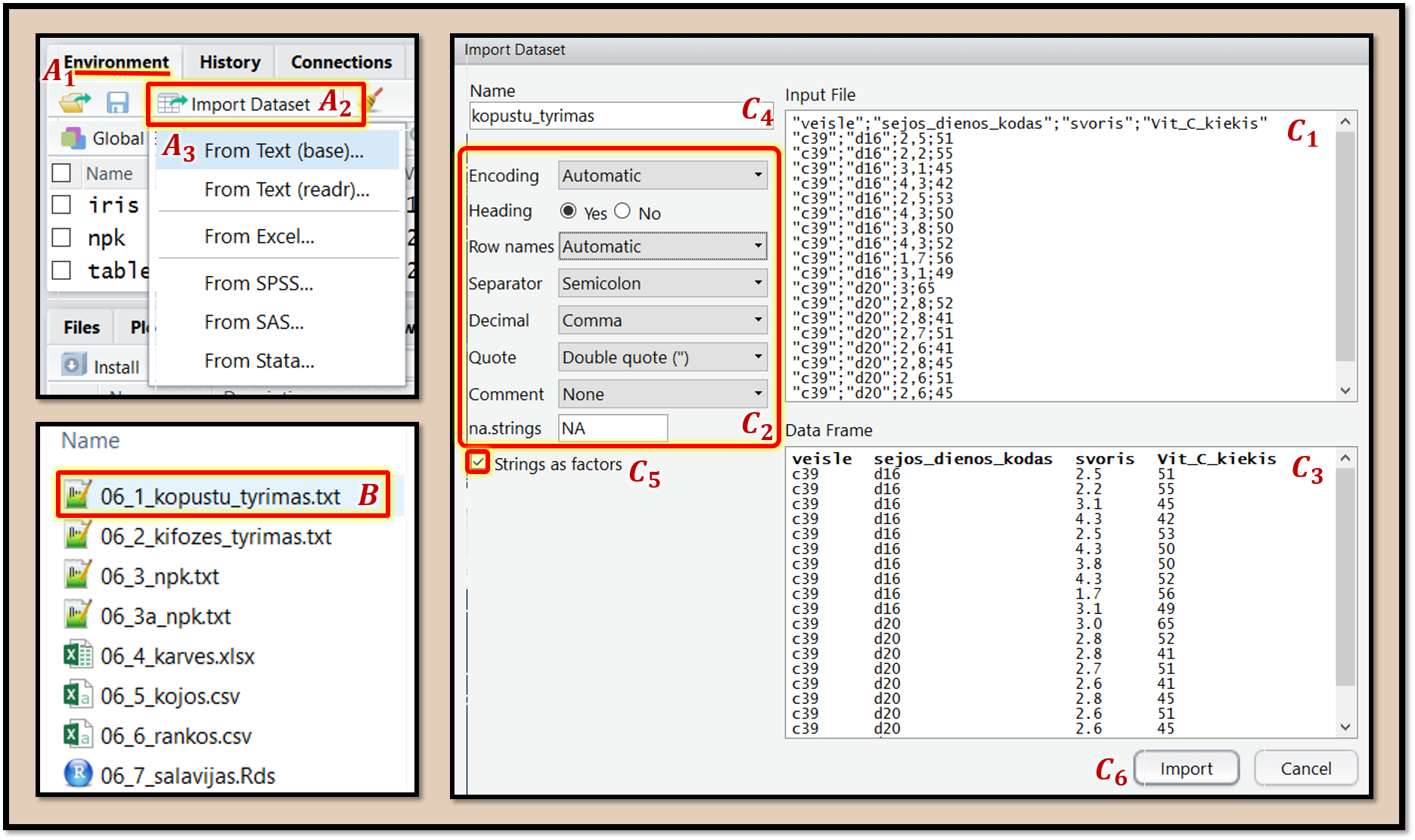
Pav. 9.9: Skirtukais atskirtų duomenų nuskaitymas iš tekstinių bylų naudojant „RStudio“ langą „Import Dataset“ „From Text (base)…“
Paveiksle 9.9 rodoma, kaip nuskaityti duomenis naudojant „RStudio“. Šios programos lange „Environment“ \((A_1)\) spaudžiame mygtuką „Import Dataset“ \((A_2)\), po to „From Text (base)“ \((A_3)\). Tai bazinis (ne tidyverse), labai automatizuotas statistinei analizei tinkamas tekstinių duomenų nuskaitymo būdas. Ko gero, labiausiai suprantamas pradedantiesiems. Atsidariusiame lange susirandame aplanką su duomenimis ir pasirenkame tekstinių duomenų bylą \((B)\). Atsidaro nuskaitymo meniu, kuriame matome pirmąsias duomenų bylos eilutes \((C_1)\), pagal jas programa automatiškai parenka nuskaitymo parametrus ir juos įrašo parametrų pasirinkimo langeliuose \((C_2)\). Dažniausiai koreguoti nereikia. Jei reikia – pakoreguojame. Apatiniame lange \((C_3)\) galime pasitikrinti, ar duomenys bus nuskaityti teisingai: stulpelių pavadinimai pajuodinti, o patys duomenys – atskiruose stulpeliuose, aiškiai atskirtuose tarpais. Belieka parašyti duomenų lentelės pavadinimą \((C_4)\), kuriame gali būti tik angliškos raidės, apatiniai brūkšniai ir skaičiai, pirmasis simbolis – raidė. Kitų simbolių, pvz., tarpų, taškų, naudoti nerekomenduoju. Uždedame varnelę ties užrašu „Strings as Factors“ \((C_5)\): tekstiniai kintamieji („strings“) bus paverčiami į faktorius („factors“) – statistinei analizei tinkamą kategorinių kintamųjų tipą. Galiausiai spaudžiame „Import“ \((C_6)\). „RStudio“ konsolėje atspausdinamas duomenų nuskaitymui naudojamas programos kodas. Norėdami jį nusikopijuoti, galite žymeklį padėti lange „Console“ ir klaviatūroje paspausti rodyklę į viršų ↑. Atsiras nuskaitymo kodas be papildomų nereikalingų simbolių, kurį patogu kopijuoti.
Tais atvejais, kai reikalingas duomenų nuskaitymo kodas, jį galite nusikopijuoti pav. 9.10 parodytu būdu.
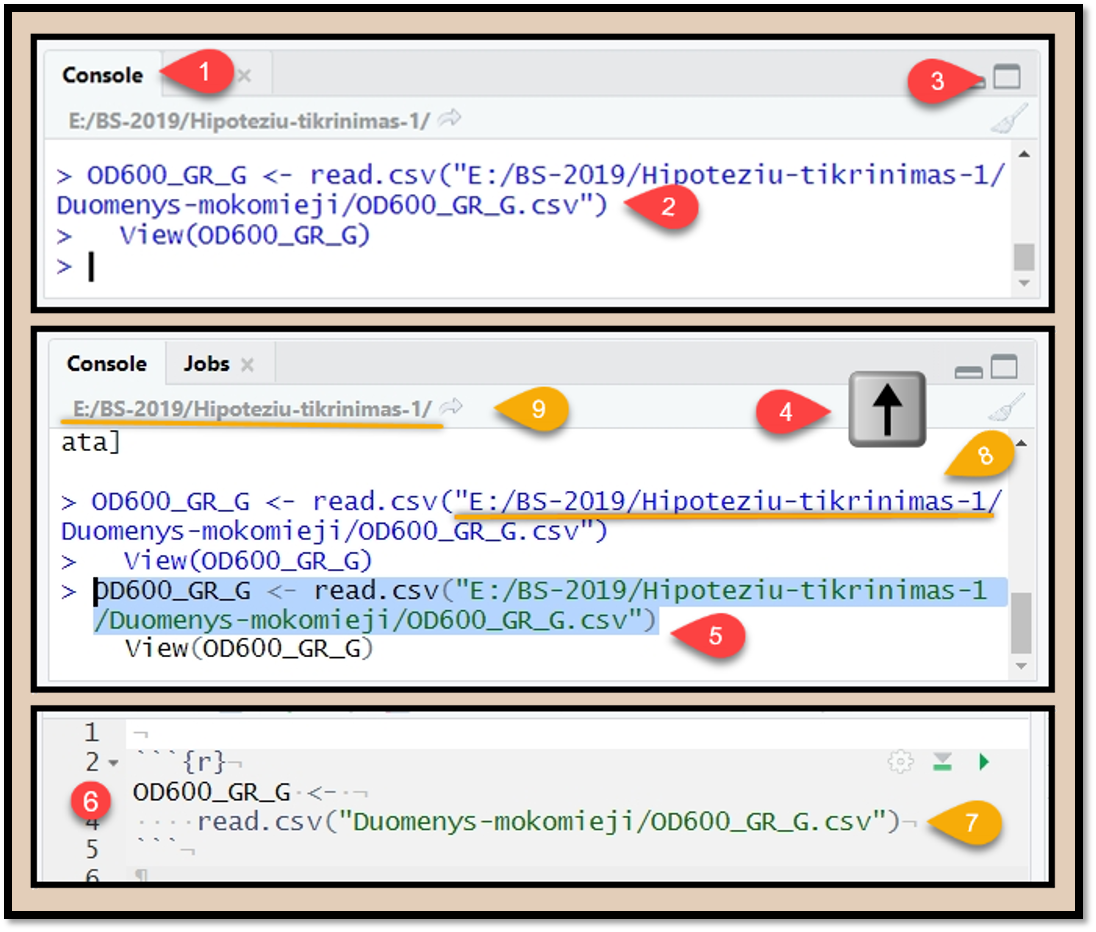
Pav. 9.10: Duomenų nuskaitymo kodo kopijavimas. Lange „Console“ (1) atsiranda programos kodas (2), sugeneruotas duomenų nuskaitymo langu (9.8). Jei kodo nesimato, padidinkite langą (3). Jei po duomenų įkėlimo vykdėte dar ir kitas komandas, padėkite pelės žymeklį „Console“ lange ir spauskite klavišą ↑ (rodyklė į viršų) vieną ar kelis kartus, kol pamatysite reikiamą kodą. Tada jį pasižymėkite, kaip rodoma (5), ir nusikopijuokite. Pastebėkite, kad eilutės pradžioje esančio „>“ simbolio kopijuoti nereikia. Tada kodą įsiklijuokite reikiamoje vietoje (6). Kai dirbate „RStudio“ projekte, tai nuskaitomos bylos pavadinimą galite sutrumpinti (7) panaikindami projekto aplanko pavadinimą (8), kuris, jei nepakeitėte aktyviojo aplanko, matomas viršutinėje „Console“ lango dalyje (9).
9.5.2 Funkcija fread()
Funkcija fread() yra paketo data.table dalis. Ji skirta labai greitam duomenų, išsaugotų tekstiniu skirtukais atskirtų reikšmių formatu, nuskaitymui. Funkcijos privalumas tas, kad ji dažniausiai automatiškai atpažįsta daugelį standartinių parametrų (pvz., koks stulpelių skirtukus, ar lentelės stulpeliai turi pavadinimus, kiek pirmųjų eilučių reikia praleisti, ar stulpeliai turi pavadinimus) ir teisingai nuskaito duomenis. Funkcija yra labai greita, nes jos branduolys parašytas programavimo kalba C++. Kiti funkcijos privalumui aprašomi straipsnyje „Convenience features of fread“ , naudojimas – dokumentacijoje (?data.table::fread).
Svarbiausi funkcijos argumentai
Svarbiausi funkcijos fread() argumentai:
input(tekstas) – duomenų bylos pavadinimas arba patys duomenys (pavyzdys skyriuje „Pavyzdžiai: fread()“):- tekstinių duomenų bylos, esančios jūsų kompiuteryje, pavadinimas (įskaitant aplanko pavadinimą, jei byla ne aktyviajame aplanke);
- tekstinių duomenų bylos, esančios internete, adresas ir pavadinimas;
- duomenys: tekstas, kuriame daugiau nei viena eilutė, traktuojamas kaip duomenų lentelė;
- shell komandos – apie jas nesimokysime.
sep(tekstas) – stulpelių (reikšmių) skirtukas. Vienas simbolis. Šį skirtuką funkcijafread()įprastai atpažįsta ir parenka automatiškai. Jei skirtukas yra nestandartinis arba funkcija jį parenka neteisingai, reikia nurodyti rankiniu būdu. Įprastai būna tarpas (" "), kablelis (","), kabliataškis (";"), tabuliacija (žymima"\t") arba vertikalus brūkšnys ("|").dec(tekstas) – sveikosios ir dešimtosios skaičiaus dalies skirtukas. Pagal nutylėjimą – tai taškas (dec = "."). Jei sveikoji ir dešimtoji dalys atskirtos kableliu, kaip būna europietiško tipo formatuose, tada tai (dec = ",") reikia nurodyti rankiniu būdu.encoding(tekstas) – koduotė. Galimos reikšmės:"unknown","UTF-8"arba"Latin-1". Jei siekiama nuskaityti duomenis, kuriuose yra lietuviškų simbolių, įprastai reikalinga UTF-8 koduotė.skip(skaičius arba tekstas) – sveikasis skaičius, nurodantis, kiek eilučių bylos pradžioje turi būti praleista. Tose eilutėse įprastai yra ne duomenų lentelė, o papildoma informacija, komentarai. Jei konkreti reikšmė nenurodyta, šias eilutes funkcijafread()įprastai atpažįsta ir praleidžia automatiškai. Kitos galimos parinktys aprašytos funkcijos dokumentacijoje.nrows(skaičius) – sveikasis skaičius, nurodantis, kiek daugiausiai eilučių nuskaityti. Nurodžiusnrows = 0, nuskaitomi tik stulpelių pavadinimai ir sukuriama tuščia lentelė. Nurodžiusnrows = Inf, nuskaitomos visos eilutės.header– loginė reikšmė, kuria nurodoma, ar duomenų lentelėje pateikti stulpelių pavadinimai. JeiFALSE, stulpeliams pavadinimai sukuriami naudojant stulpelių numerius. Šį nustatymą funkcijafread()įprastai parenka automatiškai.col.names(tekstas) – jei reikia, ženklų eilučių vektorius su stulpelių pavadinimais.na.strings(tekstas) – ženklų eilučių vektorius su reikšmėmis, kurias reikia interpretuoti kaip praleistas reikšmes.quote(tekstas) – kokios rūšies kabutės naudojamos į vieną stulpelį sujungti tarpais atskirtus žodžius (viengubos'ar dvigubos"). Pagal nutylėjimą žodžiai tarp dvigubų kabučių (") interpretuojami kaip to paties stulpelio reikšmės. Jei norime pakeisti į viengubas kabutes, galime pasirinkti argumentąquote = "'".stringsAsFactors– loginė reikšmė, nurodanti, ar tekstinius kintamuosius (t. y., ženklų eilutes) interpretuoti kaip kategorinius kintamuosius? Galimo pasirinkimo variantai:FALSE(pasirenkama pagal nutylėjimą) – interpretuoti kaip tekstinius kintamuosius (angl. character, sutrumpintai chr);TRUE– paverčiama į kategorinius kintamuosius (angl. factor).
Jei jūsų kompiuteryje yra įdiegtas paketas data.table, daugiau apie funkciją fread() ir jos parametrus galite sužinoti į „R“ komandų langą suvedę:
Pavyzdžiai: fread()
Keliuose tolimesniuose pavyzdžiuose bus naudojami duomenys (arba jų fragmentai), viešai prieinami internetu . Duomenų aprašymą galite rasti čia .
Užkraukime paketą:
Pirmame pavyzdyje duomenys nuskaityti iš bylos, esančios mano kompiuteryje. Byloje stulpeliai neturi pavadinimų, pirmosios 3 eilutės – papildoma informacija (kaip matome, ji nenuskaitoma). Jūs šiuos duomenis galite atsisiųsti . Atspausdinu pirmąsias tekstinės bylos eilutes:
Source: http://calcnet.mth.cmich.edu/org/spss/V16_materials/DataSets_v16/Diseaseoutbreak.dat
Description: http://calcnet.mth.cmich.edu/org/spss/Prj_diseaseData.htm
1 33 1 1 0 1
2 35 1 1 0 1
3 6 1 1 0 0
4 60 1 1 0 1
5 18 3 1 1 0
6 26 3 1 0 0
7 6 3 1 0 0
8 31 2 1 1 1# Nuskaitome duomenis kaip tekstą (eilutė po eilutės)
tekstas <- readLines("duomenys/Diseaseoutbreak.txt")
# Atspausdiname 10 pirmų eilučių
writeLines(tekstas[1:10])
## Source: http://calcnet.mth.cmich.edu/org/spss/V16_materials/DataSets_v16/Diseaseoutbreak.dat
## Description: http://calcnet.mth.cmich.edu/org/spss/Prj_diseaseData.htm
##
## 1 33 1 1 0 1
## 2 35 1 1 0 1
## 3 6 1 1 0 0
## 4 60 1 1 0 1
## 5 18 3 1 1 0
## 6 26 3 1 0 0
## 7 6 3 1 0 0Duomenų nuskaitymas:
# Duomenys nuskaityti iš bylos, esančios kompiuteryje.
is_bylos <- fread("duomenys/Diseaseoutbreak.txt", skip = 3)head(is_bylos)
## V1 V2 V3 V4 V5 V6
## 1: 1 33 1 1 0 1
## 2: 2 35 1 1 0 1
## 3: 3 6 1 1 0 0
## 4: 4 60 1 1 0 1
## 5: 5 18 3 1 1 0
## 6: 6 26 3 1 0 0Antrame pavyzdyje duomenys nuskaityti iš bylos, esančios internete. Byloje stulpeliai neturi pavadinimų, tačiau praleistų eilučių bylos pradžioje nėra.
# Duomenys nuskaityti iš bylos, esančios internete.
is_interneto <- fread("http://calcnet.mth.cmich.edu/org/spss/V16_materials/DataSets_v16/Diseaseoutbreak.txt")## V1 V2 V3 V4 V5 V6
## 1: 1 33 1 1 0 1
## 2: 2 35 1 1 0 1
## 3: 3 6 1 1 0 0
## 4: 4 60 1 1 0 1
## 5: 5 18 3 1 1 0
## 6: 6 26 3 1 0 0Trečiame pavyzdyje nukopijuotos 9 šių duomenų eilutės, ir parašytos kaip tekstas (kabutėse). Duomenų stulpeliams suteikiau pavadinimus. Jokių kitų parametrų pateikti nereikėjo, o duomenys vis tiek buvo nuskaityti teisingai.
9.6 Fiksuoto pločio stulpelių (FWF) formatas
Tekstinis fiksuoto pločio stulpelių formatas yra toks, kai kiekvieno stulpelio duomenims įrašyti skiriamas tam tikras ženklų skaičius (plotis). Tarp stulpelių tarpų gali ir nebūti. Angliškai vadinama fixed width format, tad trumpinama FWF. Šiuo formatu saugomų duomenų pavyzdžiai pateikti žemiau.
FWF duomenų pavyzdys 1.
Atkreipkite dėmesį į reikšmę Jennifer Love, kuri būtų neteisingai nuskaityta, jei naudotume skirtukais atskirtų reikšmių formatą.
Account LastName FirstName Balance CreditLimit AccountCreated Rating
101 Reeves Keanu 9315.45 10000.00 1/17/1998 A
312 Butler Gerard 90.00 1000.00 8/6/2003 B
868 Hewitt Jennifer Love 0 17000.00 5/25/1985 B
761 Pinkett-Smith Jada 49654.87 100000.00 12/5/2006 A
317 Murray Bill 789.65 5000.00 2/5/2007 C Įprastai šio formato duomenys stulpelių pavadinimų neturi. Pavyzdyje jie pateikti tik dėl vaizdumo.
FWF duomenų pavyzdys 2.
Sakykime, kad pavyzdyje yra 3 stulpeliai greta vienas kito (be tarpų), kurių plotis po 2 simbolius.
123456
987654
654987
963852
123123
333323
963854Nuskaitymas
Nuskaitymui naudosime paketo readr funkciją read_fwf(). Sakykime, kad turime duomenis, išsaugotus, kaip objektą txt:
txt <-
("101 Reeves Keanu 9315.45 10000.00 1/17/1998 A
312 Butler Gerard 90.00 1000.00 8/6/2003 B
868 Hewitt Jennifer Love 0 17000.00 5/25/1985 B
761 Pinkett-Smith Jada 49654.87 100000.00 12/5/2006 A
317 Murray Bill 789.65 5000.00 2/5/2007 C ")Toliau reikia nurodyti ir kiekvieno stulpelio plotį ir pavadinimą. Tam „Tidyverse“ sistemoje naudojamos pagalbinės funkcijos, tokios kaip fwf_widths(), fwf_cols(), fwf_positions(), fwf_empty(), apie kurias plačiau rašome dokumentacijoje.
Panagrinėkime, kaip reiktų naudoti fwf_widths(). Pirmiausia susikuriame stulpelio ilgių ir pavadinimų vektorius, iš kurių sudarome stulpelių aprašymą (specifikaciją):
col_widths = c(8, 16, 16, 12, 14, 16, 7)
col_names = c("account", "last_name", "first_name", "balance", "credit_limit",
"account_created", "rating")
col_spec_a <- fwf_widths(col_widths, col_names)Tada nuskaitome duomenis:
Duomenis atspausdiname. „R“ kai kuriuos stulpelius atspausdina glaudžiau, ilgas reikšmes pažymi ~. Tai daroma tik dėl to, kad lentelė būtų atspausdinama kompaktiškai, tačiau atmintyje yra tokios reikšmės, kokios turi būti (t. y., pilni pavadinimai).
duomenys_fwf_1a
## # A tibble: 5 x 7
## account last_name first_name balance credit_limit account_created rating
## <dbl> <chr> <chr> <dbl> <dbl> <chr> <chr>
## 1 101 Reeves Keanu 9315. 10000 1/17/1998 A
## 2 312 Butler Gerard 90 1000 8/6/2003 B
## 3 868 Hewitt Jennifer Lo~ 0 17000 5/25/1985 B
## 4 761 Pinkett-Smith Jada 49655. 100000 12/5/2006 A
## 5 317 Murray Bill 790. 5000 2/5/2007 CŠiuo atveju funkcija fwf_cols() būtų netgi patogesnė, nes šalia pavadinimo iš karto nurodomas stulpelio plotis:
col_spec_b <- fwf_cols(account = 8,
last_name = 16,
first_name = 16,
balance = 12,
credit_limit = 14,
account_created = 16,
rating = 7)Nuskaitymas vykdomas analogiškai:
duomenys_fwf_1b
## # A tibble: 5 x 7
## account last_name first_name balance credit_limit account_created rating
## <dbl> <chr> <chr> <dbl> <dbl> <chr> <chr>
## 1 101 Reeves Keanu 9315. 10000 1/17/1998 A
## 2 312 Butler Gerard 90 1000 8/6/2003 B
## 3 868 Hewitt Jennifer Lo~ 0 17000 5/25/1985 B
## 4 761 Pinkett-Smith Jada 49655. 100000 12/5/2006 A
## 5 317 Murray Bill 790. 5000 2/5/2007 CPažiūrėkime, kaip galima nuskaityti antro FWF pavyzdžio duomenis ir kodėl svarbu iš anksto žinoti, kokio pločio yra duomenų stulpeliai.
duomenys_fwf_2a
## # A tibble: 7 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 12 34 56
## 2 98 76 54
## 3 65 49 87
## 4 96 38 52
## 5 12 31 23
## 6 33 33 23
## 7 96 38 54duomenys_fwf_2b
## # A tibble: 7 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 12 3 456
## 2 98 7 654
## 3 65 4 987
## 4 96 3 852
## 5 12 3 123
## 6 33 3 323
## 7 96 3 854duomenys_fwf_2c
## # A tibble: 7 x 6
## a b c d e f
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 2 3 4 5 6
## 2 9 8 7 6 5 4
## 3 6 5 4 9 8 7
## 4 9 6 3 8 5 2
## 5 1 2 3 1 2 3
## 6 3 3 3 3 2 3
## 7 9 6 3 8 5 4Pirmasis read_fwf() argumentas gali būti tiek objektas su tekstu, tiek tekstinės bylos pavadinimas kompiuteryje, tiek tekstinės bylos internetinis adresas. Apie kitus argumentus rašoma dokumentacijoje.
Kaip alternatyva gali būti naudojama bazinės „R“ sistemos funkcija read.fwf().
9.7 Kitų programų duomenų formatai
Kitų, šiame skyriuje nenurodytų duomenų formatų nuskaitymui yra sukurta daugybė „R“ paketų. Įvairių statistinių programų formatams nuskaityti gali būti naudojamos paketų haven („Tidyverse“ paketas) bei foreign (bazinis) funkcijos. Jei norite nuskaityti tam tikro specifinio formato duomenis, tinkamiausių funkcijų rekomenduoju ieškoti internetinės paieškos svetainėse, tarkim www.google.com, nurodant programos „R“ pavadinimą, duomenų formatą, pvz., „How to read MATLAB data into R“.
9.8 Duomenų suvedimas: naujos duomenų lentelės kūrimas
Jei turite nedidelę duomenų lentelę, kurią norite suvesti naudodamiesi klaviatūra, arba tokią, kurią galima nukopijuoti pažymėjus pele, pvz., iš internetinės svetainės, yra keletas galimybių tai atlikti programa „R“.
9.8.1 Funkcijos edit() ir fix()
Funkcijos edit() ir fix() atidaro duomenų įvedimo bei koregavimo lentelę. Šioms funkcijoms turi būti nurodyta egzistuojanti arba sukuriama nauja lentelė kaip daroma šiame pavyzdyje:
SVARBU: jei neatliksite priskyrimo (pvz., duomenys <-), duomenys nebus išsaugoti „R“ atmintyje.
Analogišką veiksmą atlieka ir šis kodas:
9.8.2 Funkcija Rcmdr::editDataset()
Panaši lentelė atidaroma naudojant paketo Rcmdr funkcijas. Pirmiausia turi būti užkraunamas papildinys „R Commander“, kuris iš esmės yra dar vienas programos „R“ (bet ne „RStudio“) langas. Tada naudojant editDataset() atidaroma duomenų įvedimo ir koregavimo lentelė.
9.8.3 Funkcijos data.frame() ir tibble()
Alternatyvus būdas – suvesti duomenis kaip „R“ kodą. Tam gali būti naudojamos funkcijos data.frame() ar tibble::tibble() (atkreipkite dėmesį, kad funkcijos pavadinime nėra raidės r), kurioms kiekvienas stulpelis pateikiamas kaip vektorius.
9.8.4 Funkcija tibble::tribble()
Naudojant paketo tibble funkciją tribble() (atkreipkite dėmesį, kad funkcijos pavadinime yra raidė r, reiškianti row-wise – eilučių kryptimi), stulpelių pavadinimai nurodomi parašant operatorių ~ ir kiekviena įvedama reikšmė atskiriama kableliu, kaip šiame pavyzdyje:
9.8.5 Tekstinių duomenų nuskaitymo funkcijos
Dar viena alternatyva, ypač tinkanti, jei duomenys yra kopijuojami pažymėjus pele, naudoti tekstiniams duomenims nuskaityti skirtas funkcijas, tokias kaip read_table(), read_csv() arba fread(), aprašytas skyriuje „9.5 Skirtukais atskirtų reikšmių (SAR) formatas“. Šiuo atveju duomenys suvedami kaip tekstas, parašytas kabutėse. Pavyzdyje duomenys pateikti CSV formatu:
Duomenų nuskaitymo funkcija ir jos parametrai turi tikti suvedamų duomenų formatui, visai kaip duomenų, nuskaitomų iš tekstinių bylų, atveju.
Proceso eiga turėtų būti daugmaž tokia:
- Nusikopijuojame duomenis;
- Programoje „R“ užrašome funkcijos pavadinimą bei sukuriamo objekto pavadinimą, pvz.:
- Įdedame kabučių ženklą iš naujos eilutės prie kairiojo krašto. Kabutės gali būti viengubos arba dvigubos priklausomai nuo duomenų turinio:
- Tarp kabučių įklijuojame duomenis, jei reikia, pakoreguojame formatavimą. Atkreipkite dėmesį, kad visas įklijuotas tekstas turi būti nuspalvintas viena tekstui būdinga spalva.
- Įvykdykite komandą ir duomenis nuskaitykite.
Užduotis 9.7
- Paveiksle 9.11 pateikta lentelė. Suveskite ją naudodami programos „R“ galimybes, atvaizduokite duomenis sklaidos diagrama. Galiausiai lentelę išsaugokite programos „Excel“ formatu. Parinkite „R“ kintamiesiems tinkamus stulpelių pavadinimus.
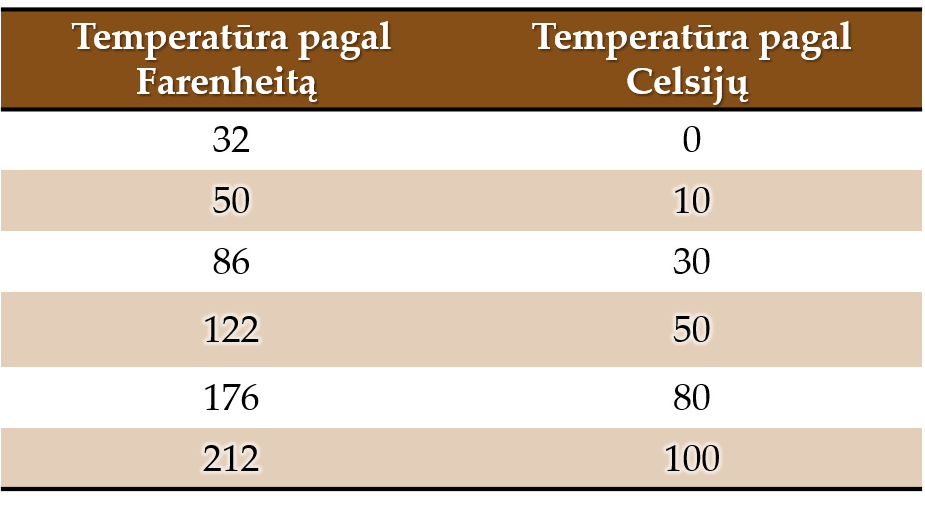
Pav. 9.11: Temperatūra pagal Farenheitą ir pagal Celsijų.