11. Skaitinės suvestinės
Aprašomosios statistikos esmė – atlikti ir pateikti skaitines ir/arba grafines duomenų suvestines, kurios glaustai perteikia esminius turimų duomenų bruožus. Praeituose skyriuose išmokome duomenis pasiversti į tinkamą statistinei analizei formatą. Dabar išmoksime pasidaryti bazines suvestines programiškai.
Duomenys
Šio skyriaus pavyzdžiuose naudosime sumažintą duomenų lentelės iris variantą – paimsime tik pirmą (Sepal.Length) ir paskutinį (Species) stulpelius:
head(iris2)
## Sepal.Length Species
## 1 5.1 setosa
## 2 4.9 setosa
## 3 4.7 setosa
## 4 4.6 setosa
## 5 5.0 setosa
## 6 5.4 setosaglimpse(iris2)
## Rows: 150
## Columns: 2
## $ Sepal.Length <dbl> 5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9, 5.4,...
## $ Species <fct> setosa, setosa, setosa, setosa, setosa, setosa, setosa...Kita duomenų lentelė – pavyzdys_3 – bus sukurta naudojant programos kodą:
pavyzdys_3 <- tibble(
lapu_skaicius = c(24L, 22L, 28L, 25L, 25L),
lapu_ilgis = c(1.3, NA, 2.2, 1.1, 1.6),
kvapo_stiprumas = ordered(c("silpnas", "vidutinis", "stiprus", "stiprus", NA)),
ziedu_spalva = factor(c("raudona", "geltona", "geltona", "balta", "balta")),
ar_augo_lauke = c(FALSE, TRUE, TRUE, FALSE, TRUE),
komentaras = c("-", "-", "tirta ryte", "-", "-")
)print(pavyzdys_3)
## # A tibble: 5 x 6
## lapu_skaicius lapu_ilgis kvapo_stiprumas ziedu_spalva ar_augo_lauke komentaras
## <int> <dbl> <ord> <fct> <lgl> <chr>
## 1 24 1.3 silpnas raudona FALSE -
## 2 22 NA vidutinis geltona TRUE -
## 3 28 2.2 stiprus geltona TRUE tirta ryte
## 4 25 1.1 stiprus balta FALSE -
## 5 25 1.6 <NA> balta TRUE -glimpse(pavyzdys_3)
## Rows: 5
## Columns: 6
## $ lapu_skaicius <int> 24, 22, 28, 25, 25
## $ lapu_ilgis <dbl> 1.3, NA, 2.2, 1.1, 1.6
## $ kvapo_stiprumas <ord> silpnas, vidutinis, stiprus, stiprus, NA
## $ ziedu_spalva <fct> raudona, geltona, geltona, balta, balta
## $ ar_augo_lauke <lgl> FALSE, TRUE, TRUE, FALSE, TRUE
## $ komentaras <chr> "-", "-", "tirta ryte", "-", "-"Paketo dplyr funkcija glimpse() (žvilgtelėti į duomenis) yra funkcijos str() analogas, duomenis pateikiantis tvarkingiau.
Užduotis 11.1
- Naudodami funkciją
dplyr::glimpse()prisiminkime esminius duomenų lentelės iris bruožus. - Naudodami funkcijas
dplyr::glimpse()irstr()patyrinėkite duomenų lentelę iris. Kuo skiriasi rezultatas?
11.1 Suvestinės tidyverse būdu
Sistemoje tidyverse statistinėms suvestinėms daryti įprastai naudojamos šios funkcijos iš paketo dplyr:
count()– dažnių lentelių sudarymas (suvestinių funkcija, kurios rezultatas – dažnių lentelė);summarise()arbasummarize()– viena iš pagrindinių dplyr funkcijų, skirta darbui su viena duomenų lentele. Ji skirta suvestinių skaičiavimui, tad duomenų lentelės dydį redukuoja iki suvestinėms reikalingo dydžio lentelės. Rezultatas yra duomenų lentelė (ne sąrašas ar matrica);group_by()– eilučių grupavimas (vėliau skaičiavimai, pvz., naudojantsummarise(), bus vykdomi kiekvienai grupei atskirai);ungroup()– grupavimo panaikinimas.
Dažnių lentelės sudarymas:
# Naudojimo principas (pavadinimai be kabučių)
duomenu_lentele %>%
count(kategorinio_kintamojo_pavadinimas, kategorinio_kintamojo_pavadinimas_2)Suvestinė visai imčiai:
# Naudojimo principas (pavadinimai be kabučių)
duomenu_lentele %>%
summarise(rezultato_pavadinimas = suvestines_funkcija(kintamojo_pavadinimas))Suvestinės pogrupiams:
# Naudojimo principas (pavadinimai be kabučių)
duomenu_lentele %>%
group_by(kategorinio_kintamojo_pavadinimas, kategorinio_kintamojo_pavadinimas_2) %>%
summarise(rezultato_pavadinimas = suvestines_funkcija(kintamojo_pavadinimas))11.1.1 Suvestinių funkcijos naudojamos su summarise()
Tam, kad suvestinių funkciją būtų galima naudoti summarise() skliaustuose, ji turi tenkinti tokias sąlygas:
- Funkcija turi būti skirta darbui su duomenų eilutėmis – vektoriais, o ne kito tipo duomenimis;
- Funkcijos rezultatas turi būti lygiai vienas skaičius. Kitu atveju
summarise()rodys klaidą.
Naudingos suvestinių funkcijos, tinkamos naudoti su summarise() (vietoje taško reikia įrašyti kintamojo pavadinimą):
- Duomenų centras:
mean(.)– vidurkis;mean(., trim = .10)– 10% nupjautinis vidurkis. Skaičių galima keisti nuo 0 iki 0.5;median(.)– mediana;DescTools::Hmean(.)– harmoninis vidurkis;DescTools::Gmean(.)– geometrinis vidurkis.
- Sklaida:
sd(.)– standartinis nuokrypis,var(.)– dispersija;IQR(.)– IQR;mad(.)– MAD.
- Kitos padėties statistikos:
min(.)– mažiausia reikšmė;max(.)– didžiausia reikšmė;quantile(. , probs = 0.25),quantile(. , probs = 0.75)– 25% ir 75% procentiliai. Skaičiųprobsgalima keisti nuo 0 iki 1.
- Pozicija (eilučių atžvilgiu):
first(.)– pirmoji reikšmė pagal eilę lentelėje;last(.)– paskutinė reikšmė pagal eilę lentelėje;nth(. , n = 2)– n-toji reikšmė pagal eilę lentelėje (šiuo atveju – antroji reikšmė).
- Skaičius, dydis:
n()– imties arba grupės dydis. Pastebėkite, kad skliaustuose nieko nerašoma;n_distinct()– unikalių (nepasikartojančių) reikšmių skaičius;sum(is.na(.))– trūkstamų reikšmių skaičius;sum(!is.na(.))– netrūkstamų reikšmių skaičius.
- Skirstinio forma:
DescTools::Kurt()– eksceso koeficientas (angl., excess kurtosis);DescTools::Skew()– asimetrijos koeficientas (angl., skewness).
Jei duomenyse yra trūkstamų reikšmių, tai daugumos iš šių funkcijų skliaustuose galima nurodyti: na.rm = TRUE. Taip bus daromos suvestinės prieš tai pašalinus trūkstamas reikšmes. Alternatyva – papildomai naudoti funkciją na.omit(), pvz., sd(na.omit(x)).
11.1.2 Pavyzdžiai
Dažnių lentelė pagal Species:
iris_suvestine1 <- iris %>% count(Species)
iris_suvestine1
## Species n
## 1 setosa 50
## 2 versicolor 50
## 3 virginica 50Suvestinėms visai imčiai naudojamos tik Sepal.Length reikšmės (nors jomis apsiriboti nebūtina):
iris_suvestine2 <-
iris %>%
summarise(
vidurkis = mean(Sepal.Length),
st_nuokrypis = sd(Sepal.Length),
mediana = median(Sepal.Length),
mad = mad(Sepal.Length),
harmoninis_vid = DescTools::Hmean(Sepal.Length),
imties_dydis = n()
)
iris_suvestine2
## vidurkis st_nuokrypis mediana mad harmoninis_vid imties_dydis
## 1 5.843333 0.8280661 5.8 1.03782 5.728905 150Suvestinės pogrupiams – papildomai pridedama tik viena eilutė su group_by() (taip nurodoma, pagal ką sudaryti grupes):
iris_suvestine3 <-
iris %>%
group_by(Species) %>%
summarise(
vidurkis = mean(Sepal.Length),
st_nuokrypis = sd(Sepal.Length),
mediana = median(Sepal.Length),
mad = mad(Sepal.Length),
harmoninis_vid = DescTools::Hmean(Sepal.Length),
imties_dydis = n()
)
iris_suvestine3
## # A tibble: 3 x 7
## Species vidurkis st_nuokrypis mediana mad harmoninis_vid imties_dydis
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
## 1 setosa 5.01 0.352 5 0.297 4.98 50
## 2 versicolor 5.94 0.516 5.9 0.519 5.89 50
## 3 virginica 6.59 0.636 6.5 0.593 6.53 50Užduotis 11.2 Naudodami tidyverse sistemos būdą, atlikite duomenų lentelių BOD, chickwts, OrchardSprays bei PlantGrowth kintamųjų reikšmių suvestines pogrupiais:
- Iš pradžių kiekvienam kintamajam (visai imčiai, ne pogrupiams) atlikite suvestines atskirai. Būtinai įvertinkite, kokia simetrija/asimetrija.
- Po to pasirinkite vieną kategorinį kintamąjį ir suvestines atlikite visiems likusiems kintamiesiems skaidydami į pogrupius.
11.2 Suvestinės baziniu R būdu
11.2.1 Funkcija summary()
Funkcija summary() suvestinę atlieka kiekvienam duomenų lentelės kintamajam atskirai. Pastebėkite, kad suvestinės tipas parenkamas pagal kintamojo tipą.
summary(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species
## setosa :50
## versicolor:50
## virginica :50
##
##
## summary(pavyzdys_3)
## lapu_skaicius lapu_ilgis kvapo_stiprumas ziedu_spalva ar_augo_lauke
## Min. :22.0 Min. :1.10 silpnas :1 balta :2 Mode :logical
## 1st Qu.:24.0 1st Qu.:1.25 stiprus :2 geltona:2 FALSE:2
## Median :25.0 Median :1.45 vidutinis:1 raudona:1 TRUE :3
## Mean :24.8 Mean :1.55 NA's :1
## 3rd Qu.:25.0 3rd Qu.:1.75
## Max. :28.0 Max. :2.20
## NA's :1
## komentaras
## Length:5
## Class :character
## Mode :character
##
##
##
## Kiekybiniams kintamiesiems pateikiama penkiaskaitė suvestinė ir vidurkis bei nurodoma, kiek yra praleistų reikšmių (NA – praleista, neįrašyta reikšmė, angl. not available).
Kategoriniams kintamiesiems išvardijamos kategorijos ir jų dažnis. Jei kategorijų daugiau nei 5, išvardijamos penkios pirmosios kategorijos, o ties kitomis parašoma “Others:” ir parašoma, kiek kitose kategorijose yra narių.
Atkreipkite dėmesį, jog loginio kintamojo suvestinėje parašoma kintamojo klasė „Mode :logical“ ir nurodomas TRUE ir FALSE reikšmių skaičius. Tuo tarpu, simbolių eilutėms (character) nurodoma klasė „Class :character“ ir reikšmių skaičius, detalesnė suvestinė apskritai neatliekama.
Užduotis 11.3
- Naudodami funkciją
summary()atlikite duomenų lentelių BOD, chickwts, Orange bei swiss kintamųjų reikšmių suvestines. - Atidžiai peržvelkite rezultatus. Įsitikinkite, kad suprantate visus niuansus.
Suvestines galima atlikti iš vienam stulpeliui atskirai naudojant $ operatorių. Tai ypač naudinga tiriant kategorinius kintamuosius, kai kategorijų daugiau nei 5.
Užduotis 11.4 Naudodami funkciją summary():
- Kiekvienam lentelės chickwts stulpeliui atskirai atlikite po suvestinę.
11.2.2 Funkcija table()
Funkcija table() skirta sudaryti dažnių lenteles.
Norėdami išvengti $ operatoriaus, galime naudoti funkciją with(). Tada funkcijos table() naudojimas taps panašus į „Tidyverse“ funkcijų.
Šia funkcija galima sudaryti ir dviejų (ar daugiau) kintamųjų dažnių lenteles.
data("CO2", package = "datasets")
glimpse(CO2)
## Rows: 84
## Columns: 5
## $ Plant <ord> Qn1, Qn1, Qn1, Qn1, Qn1, Qn1, Qn1, Qn2, Qn2, Qn2, Qn2, Qn...
## $ Type <fct> Quebec, Quebec, Quebec, Quebec, Quebec, Quebec, Quebec, Q...
## $ Treatment <fct> nonchilled, nonchilled, nonchilled, nonchilled, nonchille...
## $ conc <dbl> 95, 175, 250, 350, 500, 675, 1000, 95, 175, 250, 350, 500...
## $ uptake <dbl> 16.0, 30.4, 34.8, 37.2, 35.3, 39.2, 39.7, 13.6, 27.3, 37....with(CO2, table(Type, Treatment))
## Treatment
## Type nonchilled chilled
## Quebec 21 21
## Mississippi 21 21Panaudoję as.data.frame(), galime gauti rezultatą, panašų į funkcijos count(), tik papildomai bus rodomi variantai, kur dažnis yra lygus nuliui.
with(mtcars, table(cyl, gear)) %>%
as.data.frame()
## cyl gear Freq
## 1 4 3 1
## 2 6 3 2
## 3 8 3 12
## 4 4 4 8
## 5 6 4 4
## 6 8 4 0
## 7 4 5 2
## 8 6 5 1
## 9 8 5 2Freq – dažnis (kaip dažnai reikšmė pasitaikė). Atitinka n funkcijos count() atsakyme.
mtcars %>% count(cyl, gear)
## cyl gear n
## 1 4 3 1
## 2 4 4 8
## 3 4 5 2
## 4 6 3 2
## 5 6 4 4
## 6 6 5 1
## 7 8 3 12
## 8 8 5 211.3 Paketas DescTools
Viena iš paketo DescTools paskirčių – suteikti funkcijas patogiai aprašomajai statistikai. Paketas ukraunamas parašius
Įprastai norint, kad paketas rezultatus spausdintų pakankamai tvarkingai, reikia parinti tinkamus rezultaų spausdinimo ir apvalinimo nustatymus, pvz.:
options(scipen = 8)
# DescTools formatavimo nustatymai
Fmt(abs = Fmt("abs", big.mark = "")) # Sveikieji skaičiai
Fmt(num = Fmt("num", big.mark = "")) # Realieji siaičiai
Fmt(num = Fmt("num", digits = 3)) # Realieji siaičiai
Fmt(per = Fmt("per", digits = 1)) # Procentais išreikšti siaičiai11.3.1 Trūkstamų reikšių analizė
Atliekant trūkstamų (NA) reikšmių analizę, svarbi funkcija yra is.na(.). Tačiau šiame skyriuje plačiau panagrinėsime dvi funkcijas iš paketo DescTools.
my_data %>% CountCompCases()
##
## Total rows: 87
## Complete Cases: 29 (33.3%)
##
## vname nas nas_p cifnot cifnot_p
## 1 name 0 0.0% 29 33.3%
## 2 height 6 6.9% 29 33.3%
## 3 mass 28 32.2% 35 40.2%
## 4 hair_color 5 5.7% 33 37.9%
## 5 skin_color 0 0.0% 29 33.3%
## 6 eye_color 0 0.0% 29 33.3%
## 7 birth_year 44 50.6% 50 57.5%
## 8 sex 4 4.6% 29 33.3%
## 9 gender 4 4.6% 29 33.3%
## 10 homeworld 10 11.5% 32 36.8%Complete Cases– eilučių skaičius be trūkstamų reikšmiųvname– kintamojo (stulpelio) pavadinimasnas,nas_p– trūkstamų reikšmių (NA) skaičius / procentinė dalis stuplelyjecifnot,cifnot_p(complete if not) eilučičių skaičius / procentinė dalis be trūkstamų reikšmių, kai pašalinamas nurodytas kintamasis.
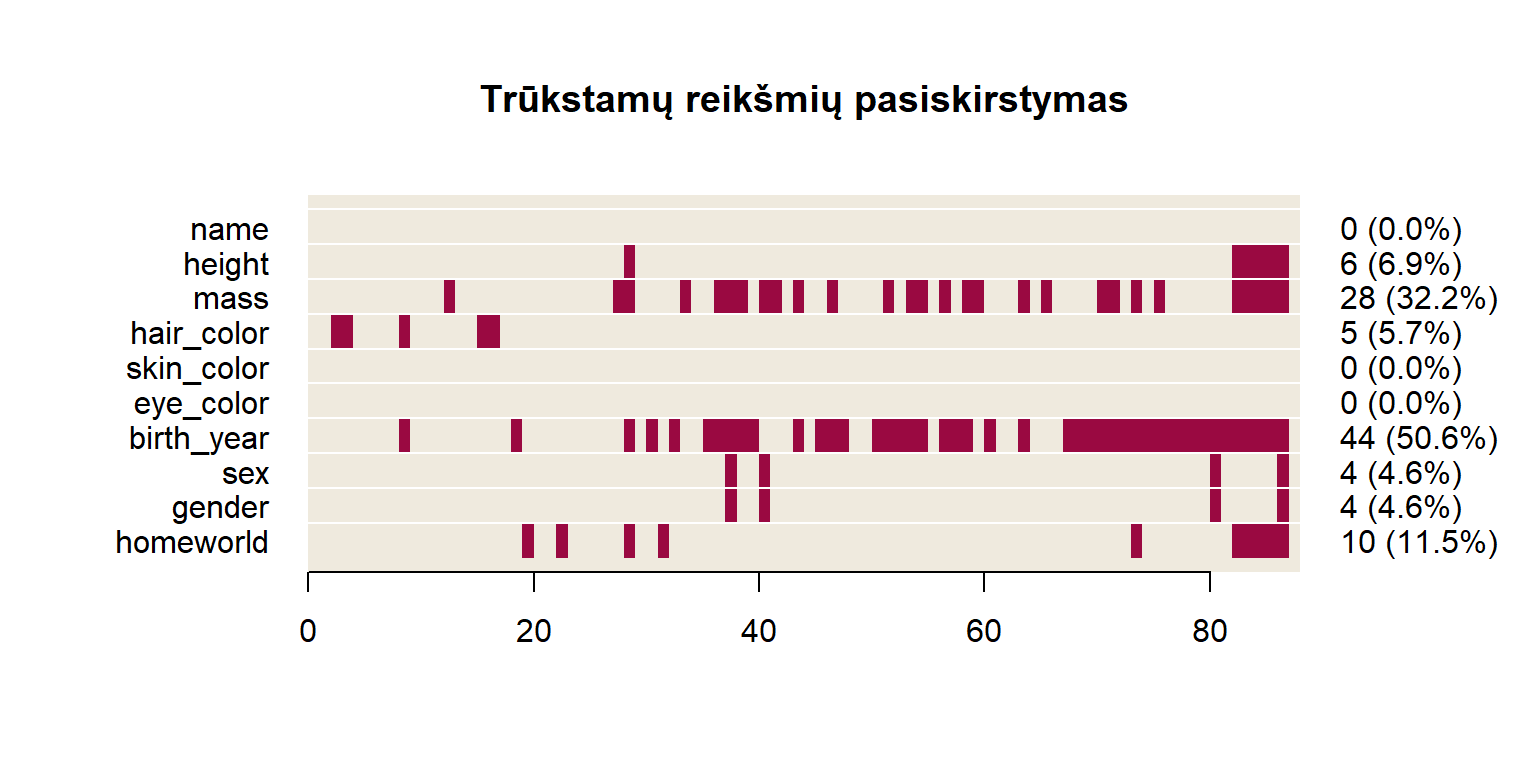
Grafike x ašyje žymimi tiriamųjų (lentelės eilučių) eilės numeriai, y ašyje – stulpelių pavadinimai. Raudonai žymimos trūkstamos reikšmės. Matome, kad pavyzdyje vieni kintamieji jų turi daugiau, kiti – mažiau.
Daugiau informacijos apie šių funkcijų naudojimą ir rezultatų interpretavimą:
11.3.2 Funkcija Desc()
Funkcija Desc() automatiškai pagal duomenų tipą parenka skaitines suvestines bei grafiką vienam kintamajam arba kintamųjų porai.
Funkcija Desc() atlieka tinkamas suvestines tik tada, jei kintamiesiems yra parinktos „R“ klasės, atitinkančios teorinius duomenų tipus.
Funkcijos taikymo pavyzdys vienam kintamajam:
with(iris, Desc(Species))
## ------------------------------------------------------------------------------
## Species (factor)
##
## length n NAs unique levels dupes
## 150 150 0 3 3 y
## 100.0% 0.0%
##
## level freq perc cumfreq cumperc
## 1 setosa 50 33.3% 50 33.3%
## 2 versicolor 50 33.3% 100 66.7%
## 3 virginica 50 33.3% 150 100.0%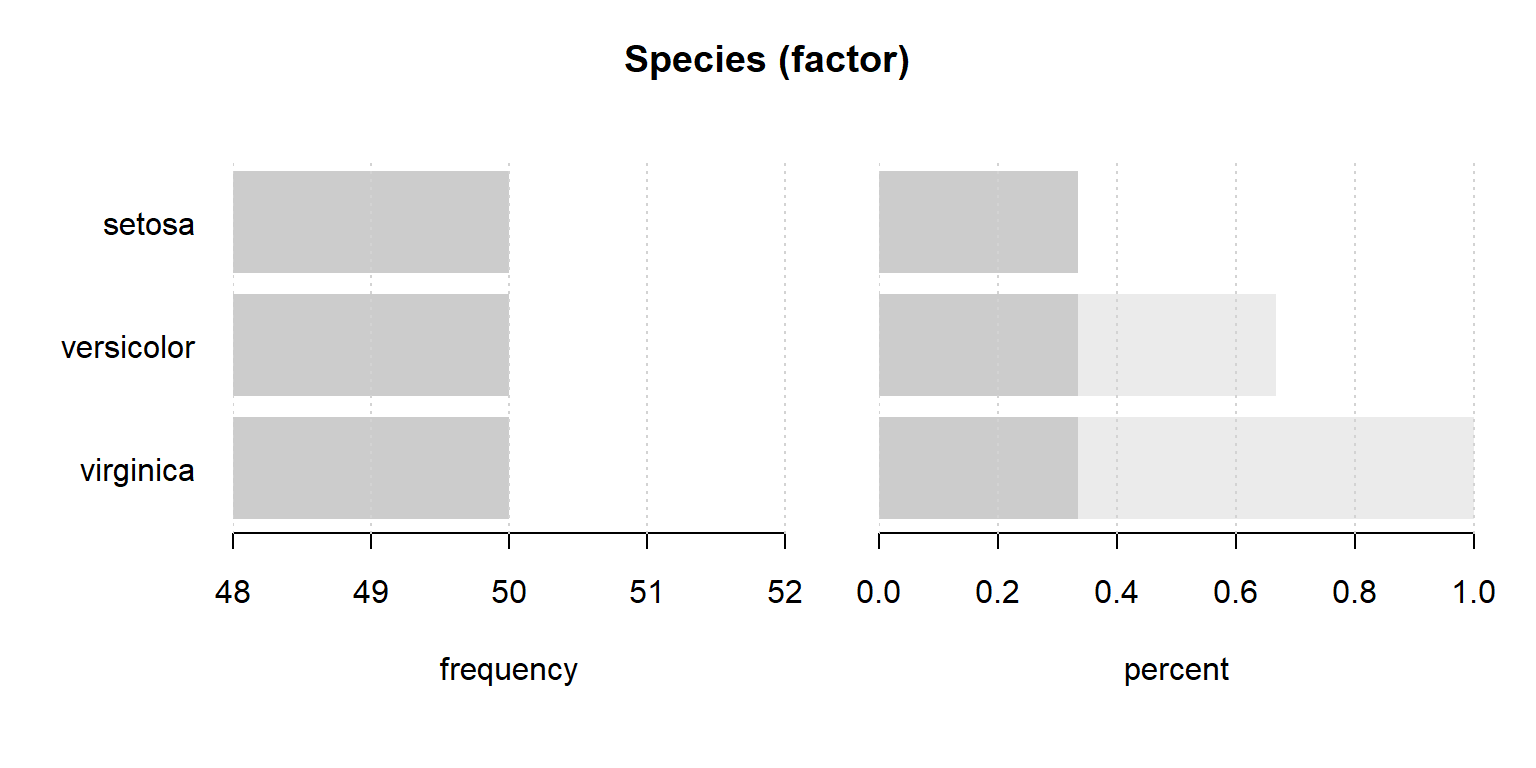
Funkcijos taikymo pavyzdys kintamųjų porai:
Desc(Sepal.Width ~ Species, data = iris)
## ------------------------------------------------------------------------------
## Sepal.Width ~ Species (iris)
##
## Summary:
## n pairs: 150, valid: 150 (100.0%), missings: 0 (0.0%), groups: 3
##
##
## setosa versicolor virginica
## mean 3.428 2.770 2.974
## median 3.400 2.800 3.000
## sd 0.379 0.314 0.322
## IQR 0.475 0.475 0.375
## n 50 50 50
## np 33.333% 33.333% 33.333%
## NAs 0 0 0
## 0s 0 0 0
##
## Kruskal-Wallis rank sum test:
## Kruskal-Wallis chi-squared = 63.571, df = 2, p-value = 1.569e-14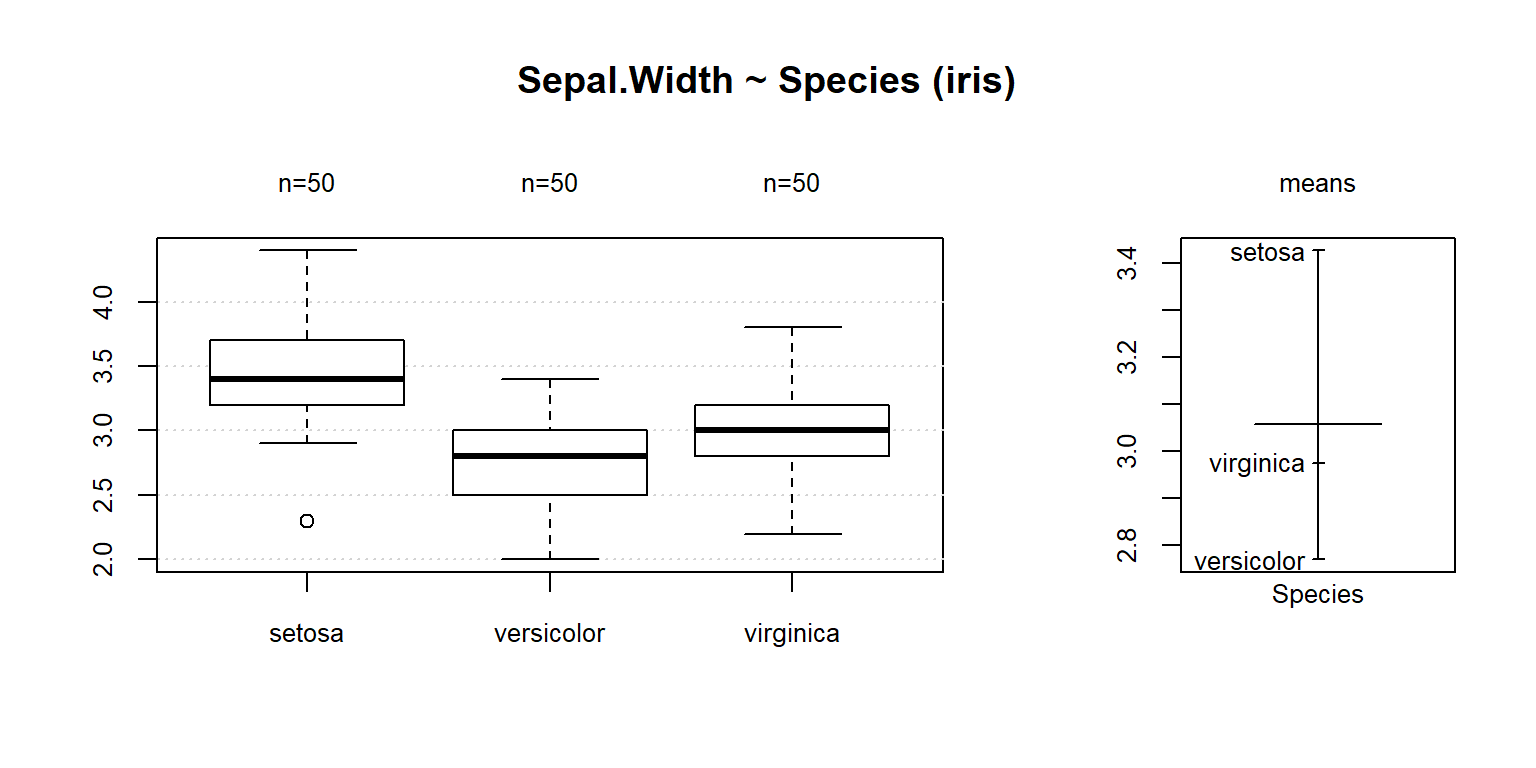
Daugiau informacijos apie šią funkciją bei jos rezultatus:
Taip pat atitinkamuose šio aprašo skyriuose:
11.3.3 Kitos DescTools funkcijos
Paketas DescTools turi daugybę kitų funkcijų aprašomajai statistikai ir kitokiai analizei. Siūlau patiems panagrinėti paketo aprašymą ir funkcijas.
Pagalbinė medžiaga atliekant aprašomają satistiką paketu DescTools:
Darbui su dažnių lentelėmis:
11.4 Paketas summarytools skaitinės suvestinės
Paketas summarytools siūlo 4 pagrindines funkcijas „greitai“ aprašomajai statistikai.
freq()absoliučių ir santykinių dažnių lentelė vienam (kategoriniam) kintamajam;ctable()porinė dažnių lentelė su eilučių ir stulpelių sumomis;descr()skaitinės vieno kintamojo aprašomosios statistikos (skaitiniams kintamiesiems);dfSummary()„greita“ statistinė suvestinė visiems duomenų lentelės stulpeliams iš karto.
Šio paketo funkcijos yra suderinamos su group_by ir suvestines gali atlikti pogrupiams.
iris %>%
descr() %>%
tb()
## Warning: `funs()` is deprecated as of dplyr 0.8.0.
## Please use a list of either functions or lambdas:
##
## # Simple named list:
## list(mean = mean, median = median)
##
## # Auto named with `tibble::lst()`:
## tibble::lst(mean, median)
##
## # Using lambdas
## list(~ mean(., trim = .2), ~ median(., na.rm = TRUE))
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_warnings()` to see where this warning was generated.
## # A tibble: 4 x 16
## variable mean sd min q1 med q3 max mad iqr cv skewness
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Petal.L~ 3.76 1.77 1 1.6 4.35 5.1 6.9 1.85 3.50 0.470 -0.269
## 2 Petal.W~ 1.20 0.762 0.1 0.3 1.3 1.8 2.5 1.04 1.5 0.636 -0.101
## 3 Sepal.L~ 5.84 0.828 4.3 5.1 5.8 6.4 7.9 1.04 1.3 0.142 0.309
## 4 Sepal.W~ 3.06 0.436 2 2.8 3 3.3 4.4 0.445 0.5 0.143 0.313
## # ... with 4 more variables: se.skewness <dbl>, kurtosis <dbl>, n.valid <dbl>,
## # pct.valid <dbl>iris %>%
group_by(Species) %>%
descr() %>%
tb()
## # A tibble: 12 x 17
## Species variable mean sd min q1 med q3 max mad iqr cv
## <fct> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 setosa Petal.L~ 1.46 0.174 1 1.4 1.5 1.6 1.9 0.148 0.175 0.119
## 2 setosa Petal.W~ 0.246 0.105 0.1 0.2 0.2 0.3 0.6 0 0.100 0.428
## 3 setosa Sepal.L~ 5.01 0.352 4.3 4.8 5 5.2 5.8 0.297 0.4 0.0704
## 4 setosa Sepal.W~ 3.43 0.379 2.3 3.2 3.4 3.7 4.4 0.371 0.475 0.111
## 5 versic~ Petal.L~ 4.26 0.470 3 4 4.35 4.6 5.1 0.519 0.600 0.110
## 6 versic~ Petal.W~ 1.33 0.198 1 1.2 1.3 1.5 1.8 0.222 0.3 0.149
## 7 versic~ Sepal.L~ 5.94 0.516 4.9 5.6 5.9 6.3 7 0.519 0.7 0.0870
## 8 versic~ Sepal.W~ 2.77 0.314 2 2.5 2.8 3 3.4 0.297 0.475 0.113
## 9 virgin~ Petal.L~ 5.55 0.552 4.5 5.1 5.55 5.9 6.9 0.667 0.775 0.0994
## 10 virgin~ Petal.W~ 2.03 0.275 1.4 1.8 2 2.3 2.5 0.297 0.500 0.136
## 11 virgin~ Sepal.L~ 6.59 0.636 4.9 6.2 6.5 6.9 7.9 0.593 0.675 0.0965
## 12 virgin~ Sepal.W~ 2.97 0.322 2.2 2.8 3 3.2 3.8 0.297 0.375 0.108
## # ... with 5 more variables: skewness <dbl>, se.skewness <dbl>, kurtosis <dbl>,
## # n.valid <dbl>, pct.valid <dbl>Plačiau apie funkcijas skaitykite paketo GitHub paskyroje ir mokomojoje medžiagoje „Introduction to summarytools“ .