10. Pasikliautinieji intervalai (PI)
Šiame skyriuje nagrinėsime pasikliautinuosius intervalus (PI): tiek klasikinius, tiek savirankos metodus, skirtus sudaryti PI.
10.1 PI sąvoka
Pasikliautinųjų intervalų (PI) sudarymas – yra vienas iš statistinių išvadų darymo būdų. Jis padeda atsakyti į klausimą, kokia yra tikroji parametro vertė nurodant tam tikrą intervalą. Pvz., koks yra vidutinis vyrų pulsas vos tik atsikėlus ar kuri dalis žmonių mėgsta šokoladą.
PI sudarymas yra tam tikras atsitiktinės paklaidos (žr. skyriuje 3.3.2), t.y., rezultatų neapibrėžtumo (atkreipkite dėmesį, kad ne duomenų, o rezultatų), įvertinimo būdas. Tai reiškia, kad jis tinka tik tada, kai imtis yra sudaryta visiškai atsitiktinai, t.y., kai imtis yra tikimybinė.
PI skaičiuoti yra prasminga tik tada, kai imtis yra visiškai atsitiktinė.
10.1.1 Statistikos skirstinys
Statistika yra funkcija (pvz., vidurkis) apskaičiuota iš duomenų (t.y., atsitiktinis dydis). Statistikos realizacija – tos funkcijos rezultatas (konkretus skaičius konkrečiai imčiai).
Kalbant apie skirstinius, pagal tai, kieno tai skirstinys, mes galime turėti kelių „lygių“ skirstinius (pav. 10.1):
- Generalinės aibės reikšmių skirstinys (angl. population distribution) – įprastai mes jo nežinome, todėl ir atliekame tyrimą.
- Imties reikšmių skirstinys (angl. sample distribution) – tai į tyrimą patekusių tiriamųjų savybių reikšmių skirstinys.
- Imties statistikų skirstinys (angl. sampling distribution) – jeigu sudarytume daug atsitiktinių imčių ir skaičiuotume jų vidurkius, tai kiekvienai imčiai turėtume po vidurkį. Vadinasi, galėtume sudaryti vidurkių skirstinį – tai ir būtų vienas iš imties statistikų pavyzdžių.
- Pakartotinės atrankos (pvz., savirankos) metodu sudarytas statistikų skirstinys (angl. resampling distribution). Apie jį plačiau pakalbėsime skyriuje „10.4 Savirankos metodai“.
{target="_blank"}.](https://www.stat.auckland.ac.nz/~wild/ISR-15/anim/1samp.Mean.SV_100.gif)
Pav. 10.1: Simuliacija: generalinės aibės, imties ir imties statistikos (vidurkio) skirstiniai. Juodi pilnaviduriai taškai vaizduoja į imtį patekusius elementus. Šaltinis .
Darant statistines išvadas, imtis turi būti atsitiktinė. Dėl šios priežasties kiekviena statistika, skaičiuota iš tokios imties, taip pat yra atsitiktinis dydis. Kiekvienas atsitiktinis dydis turi skirstinį. Pagal šį skirstinį ir yra vertinamos pasikliautinojo intervalo ribos. Klasikiniais vadinsime tuos metodus, kai statistikų skirstinys, pagal kurį skaičiuojami PI, yra aproksimuotas naudojant analitiškai išvestą formulę. Savirankos metodai statistikų skirstinį sudaro imties duomenims vykdydami daugybę perskaičiavimų.
10.1.2 PI „anatomija“
Pasikliautinąjį intervalą sudaro apatinė ir viršutinė ribos, dar vadinamos rėžiais (pažymėkime \(\hat{\theta}_{apatinis}\) ir \(\hat{\theta}_{viršutinis}\)). Norint sudaryti pasikliautinuosius intervalus, įprastai reikia žinoti taškinį statistikos įvertį (pažymėkime \(\hat{\theta}\)) ir prie jo pridėti bei iš jo atimti paklaidą.
\[\begin{equation} \hat{\theta}_{apatinis} = \hat{\theta} - paklaida_1 \\ \hat{\theta}_{viršutinis} = \hat{\theta} + paklaida_2 \tag{10.1} \end{equation}\]
Bendruoju atveju, taškinio įverčio atžvilgiu PI nebūtinai turi būti simetriški. Be to, yra metodų, kai PI įvertinimui taškinį įvertį žinoti nėra būtina. Visgi, atvaizduojant ir aprašant PI įprasta nurodyti tiek taškinį įvertį, tiek PI rėžius.
10.1.3 PI apibrėžimas
Praktikoje dažniausiai skaičiuojami 95% pasikliautinieji intervalai. Jie apibrėžiami taip: jei iš generalinės aibės imtume be galo daug atsitiktinių imčių (t.y., jei daug kartų kartotume tyrimą sudarydami vis naujas imtis) ir pagal jas sudarytume tam tikro parametro (sakykime, vidurkio) PI, tai maždaug 95 atvejais iš 100 PI būtų sudarytas taip, kad tarp jo ribų patektų ir tikroji parametro (pvz., generalinės aibės vidurkio \(\mu\)) reikšmė.
Su PI susijusi sąvoka – pasikliovimo lygmuo Q. Iš principo, tai tikimybė, rodanti, kaip dažnai intervalai būna sudaromi teisingai, jei naudojame tam tikrą PI sudarymo metodą. Kitais žodžiais kalbant, Q parodo mūsų pasitikėjimą PI sudarymo metodu (pav. 10.2).
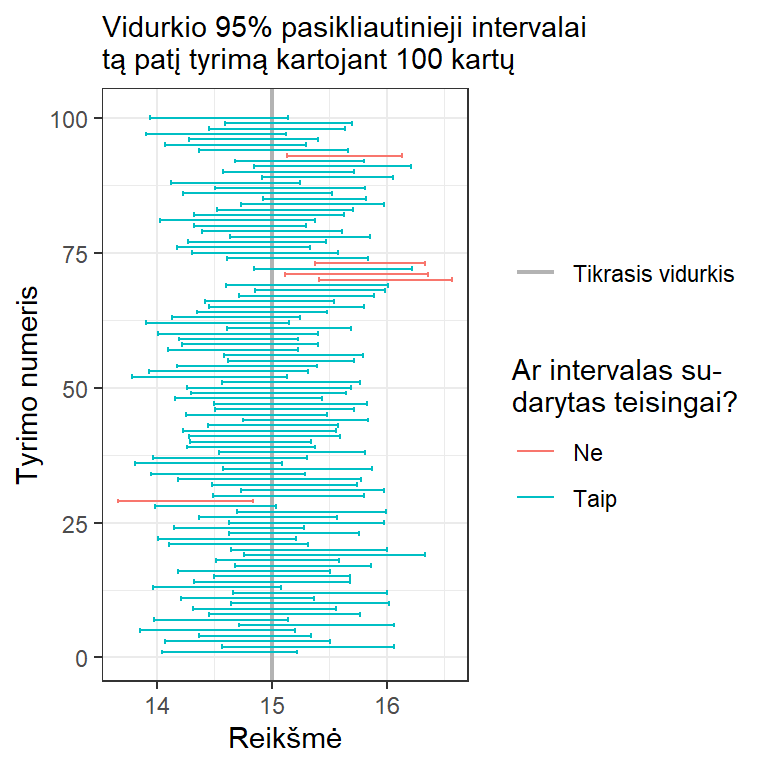
Pav. 10.2: Jei skaičiuojame 95% pasikliautinuosius intervalus, tai maždaug 95 atvejais iš 100 intervalai bus sudaryti teisingai (melsvos linijos). Tie 95% parodo mūsų pasitikėjimą intervalų sudarymo taisykle.
Klaidinga teigti, kad pasikliovimo lygmuo – tai tikimybė, jog tikroji parametro vertė patenka į intervalą. Tai reikštų, kad kartojant tyrimą PI ribos nekinta, bet keičiasi tikrojo parametro vertė. Iš tiesų yra atvirkščiai: parametro vertė nekinta, o intervalų ribos dėl imties atsitiktinumo kiekvieną kartą apskaičiuojamos šiek tiek skirtingai.
Apie tai, kas yra pasikliautinieji intervalai, plačiau paaiškinta šaltinio (Čekanavičius ir Murauskas 2014, p.25) skyriuje „Parametrų įverčiai ir jų pasikliautinieji intervalai“ (skyrius trumpas, rekomenduoju perskaityti).
10.2 Vidurkio PI
Klasikiniai PI sudarymo metodai įprastai grindžiami prielaida, kad duomenys yra normalieji. Tokiems duomenims puikiai tinka įvairūs teoriniai modeliai, išvedamos formulės.
Privalumai. Turint formulę, galima ją pertvarkyti taip, kad būtų galima apskaičiuoti bet kurį jos narį. Skaičiavimai atliekami greitai.
Trūkumai. Reikia tenkinti normalumo ir kitas prielaidas. Tinka tik kai kurioms statistikoms, tokioms kaip vidurkis. Tačiau kvartiliams ir panašioms neparametrinėms statistikoms – tokių formulių nėra.
10.2.1 Vidurkio PI, kai GA dispersija žinoma ar imtis didelė
Kai duomenys – normalieji, o generalinės aibės dispersija žinoma, vidurkio PI galima skaičiuoti pagal formulę (10.2). Situacija, kai tikrasis vidurkis nežinomas, o duomenų išsisklaidymas aplink jį (dispersija) – žinomas, įprastai yra tik hipotetinė. Tačiau formulė ganėtinai paprasta ir mokymosi tikslais iliustruoti, kaip konstruojamas PI, tinkama. Ši formulė taip pat naudojama ir tada, kai imties dydis pakankamai didelis (vienų autorių teigimu, bent 30, kitų – bent 50).
Ši formulė tinka normaliai pasiskirsčiusiems duomenims arba duomenims, kurių yra tiek daug, kad centrinė ribinė teorema ima veikti pakankamai smarkiai. (Centrinė ribinė teorema teigia, kad kuo didesnė imtis, tuo labiau jos vidurkio skirstinys supanašėja su normaliuoju.)
\[\begin{equation} \hat{\mu}_{1,2} = \overline{x} \mp z_{\left(\frac{1-Q}{2}\right)}{\sigma \over \sqrt{n}} \tag{10.2} \end{equation}\]
Formulėje:
\(\hat{\mu}_{1}\) – apatinė vidurkio pasikliautinojo intervalo riba (mažesnis skaičius);
\(\hat{\mu}_{2}\) – viršutinė vidurkio pasikliautinojo intervalo riba (didesnis skaičius);
\(\overline{x}\) – imties reikšmių vidurkis;
\(\sigma\) – generalinės aibės standartinis nuokrypis (arba imties standartinis nuokrypis, jei duomenų pakankamai daug);
\(n\) – imties dydis;
\(Q\) – pasikliovimo lygmuo (tikimybė: skaičius tarp 0 ir 1, įprastai – 0,95);
\({\left(\frac{1-Q}{2}\right)}\) – galime pažymėti kaip tikimybę \(\alpha^*\);
\(z_{\alpha^*}\) – \(z\) koeficientas – daugiklis, dar vadinamas standartinio normaliojo skirstinio \(1-\alpha^*\) lygmens kvantiliu (skaičius, priklausantis nuo norimo pasikliovimo lygmens). Jis imamas iš lentelių arba apskaičiuojamas programomis „R“, „GeoGebra“ (pav. 10.3) ar kitomis.
Formulė susideda iš 2 pagrindinių dalių: taškinio vidurkio įverčio ir paklaidos. Visa paklaida susideda iš koeficiento, priklausančio nuo norimo pasikliovimo lygmens, ir standartinės vidurkio paklaidos. Ar matote šias dalis?
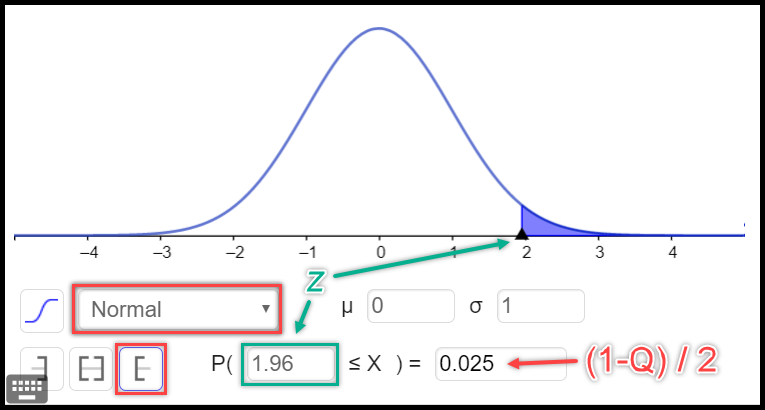
Pav. 10.3: Koeficiento \(z\) skaičiavimas programa „GeoGebra“. Naudojamas standartinis normalusis skirstinys. Koeficiento reikšmė nuo imties dydžio nepriklauso. Q – pasikliovimo lygmuo. Žalsva spalva pažymėta vieta, kur gauname atsakymą (\(z\) koeficientą), kai teisingai užpildome visus kitus laukelius.
Siekiant apsiskaičiuoti reikiamą imties dydį, kad būtų pasiektas norimas tikslumas (intervalo ilgis), gali būti naudojama iš (10.2) formulės išvesta lygtis (10.4).
Formulė su \(z\) koeficientu tinkama tada, kai žinome tikrąją generalinės aibės dispersiją \((\sigma^2)\). Arba imtyje duomenų pakankamai daug – vienų autorių teigimu \(n>50\), kitų – \(n>30\). Imties skirstinys turi būti normalusis. Tai ypač svarbu mažoms imtims.
Mažoms normaliai pasiskirsčiusioms imtims taikoma kita formulė, kurioje naudojamas \(t\) koeficientas (žr. 10.2.2 skyriuje).
Užduotis 10.1
- Išmatuotas \(100\) studentų cholesterolio kiekis kraujyje. Gautas vidurkis \(310\frac{\mu mol}{l}\). Koks cholesterolio kiekio kraujyje vidurkio \(95\%\) pasikliautinasis intervalas, jeigu šio dydžio standartinis nuokrypis studentų populiacijoje yra \(35\frac{\mu mol}{l}\)?
10.2.2 Vidurkio PI, kai GA dispersija nežinoma
Kai GA dispersija nežinoma, tada vidurkio PI skaičiavimo formulėje naudojame iš duomenų apskaičiuotą dispersiją. Tokiu atveju vietoje \(z\) koeficiento reikia naudoti \(t\) koeficientą, kurio dydis priklauso nuo imties dydžio. Tad formulė (10.3) įprastai yra tinkamesnė, kai analizuojame mūsų pačių surinktus duomenis. Ši formulė tinka normaliai pasiskirsčiusiems duomenims, arba duomenims, kurių yra tiek daug, kad ima veikti centrinė ribinė teorema. (Centrinė ribinė teorema teigia, kad kuo didesnė imtis, tuo labiau jos vidurkio skirstinys supanašėja su normaliuoju.)
\[\begin{equation} \hat{\mu}_{1,2} = \overline{x} \mp t_{\left(\frac{1-Q}{2}\right)}^{(n-1)} {s \over \sqrt{n}} \tag{10.3} \end{equation}\]
Formulėje:
\(\hat{\mu}_{1}\) – apatinė vidurkio pasikliautinojo intervalo riba (mažesnis skaičius);
\(\hat{\mu}_{2}\) – viršutinė vidurkio pasikliautinojo intervalo riba (didesnis skaičius);
\(\overline{x}\) – imties reikšmių vidurkis;
\(s\) – imties reikšmių standartinis nuokrypis;
\(n\) – imties dydis;
\(Q\) – pasikliovimo lygmuo (tikimybė: skaičius tarp 0 ir 1, įprastai 0,95);
\({\left(\frac{1-Q}{2}\right)}\) – galime pažymėti kaip tikimybę \(\alpha^*\);
\(t_{\alpha^*}^{(n-1)}\) – daugiklis, dar vadinamas Stjudento koeficientu arba Stjudento skirstinio (su \(n-1\) laisvės laipsnių) \(1-\alpha^*\) lygmens kvantiliu (skaičius, priklausantis nuo norimo pasikliovimo lygmens). Jis imamas iš lentelių arba apskaičiuojamas programomis „R“, „GeoGebra“ (pav. 10.4) ar kitomis.
Ar matote, kur formulėje yra taškinis vidurkio įvertis ir kur – paklaida?
Ši formulė tinka normaliai pasiskirsčiusiems duomenims, arba duomenims, kurių yra tiek daug, kad ima veikti centrinė ribinė teorema. (Centrinė ribinė teorema teigia, kad kuo didesnė imtis, tuo labiau jos vidurkio skirstinys supanašėja su normaliuoju.) Jei skaičiavimus atliekame imties duomenims, formulė su \(t\) koeficientu yra universalesnė: tinka ir tada, kai imtis maža. Jei taškų yra iki 15 – pasiskirstymas privalo būti idealiai normalusis. Pastaba: kai imtis mažesnė nei 20, statistinių normalumo prielaidos tikrinimo metodų (žr. 16 skyriuje) rezultatai yra nepatikimi.
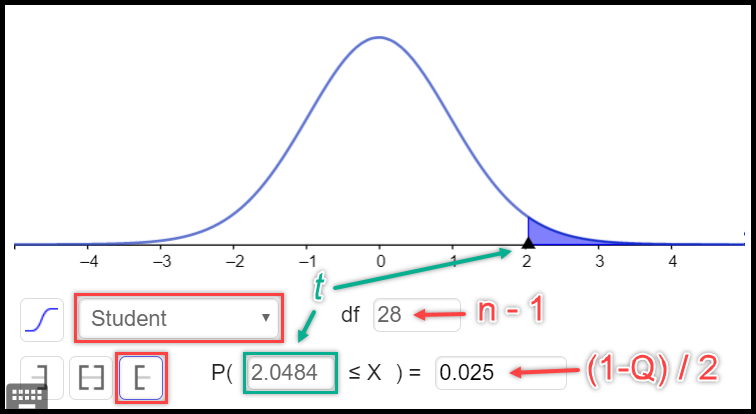
Pav. 10.4: Koeficiento \(t\) skaičiavimas programa „GeoGebra“. Naudojamas Stjudento skirstinys, kurio forma priklauso nuo imties dydžio (n). Q – pasikliovimo lygmuo. Žalsva spalva pažymėta vieta, kur gauname atsakymą (\(t\) koeficientą), kai teisingai užpildome visus kitus laukelius.
10.2.3 Imties dydžio skaičiavimas norimam vidurkio PI ilgiui
Jei norime apskaičiuoti reikiamą imties dydį, kurio reikia norimam tikslumui pasiekti, tai padaryti iš formulės su \(t\) koeficientu (10.3) yra ganėtinai sudėtinga. Todėl tokiai situacijai įprastai naudojama formulė su \(z\) koeficientu (10.2), kurio reikšmė nepriklauso nuo imties dydžio. Iš formulės išreikštą imties dydį aprašo lygtis (10.4):
\[\begin{equation} n = \left( {2 \cdot \sigma\cdot z_{\left(\frac{1-Q}{2}\right)} } \over \Delta\hat{\mu} \right)^2 \tag{10.4} \end{equation}\]
Formulėje:
\(n\) – imties dydis;
\(\Delta\hat{\mu}\) – vidurkio pasikliautinojo intervalo ilgis;
\(\sigma\) – (hipotetinis) standartinis nuokrypis;
\(Q\) – pasikliovimo lygmuo (tikimybė);
\({\left(\frac{1-Q}{2}\right)}\) – galime pažymėti kaip tikimybę \(\alpha\);
\(z_{\alpha}\) – \(z\) koeficientas – daugiklis, dar vadinamas standartinio normaliojo skirstinio \(1-\alpha\) lygmens kvantiliu (skaičius, priklausantis nuo norimo pasikliovimo lygmens).
Rezultatą apvaliname iki sveikųjų skaičių į didesnių reikšmių pusę, tarkime, 60,02 → 61. Kitu atveju intervalas bus per trumpas (t.y., nebus pasiektas norimas tikslumas).
Statistikos vadovėliuose naudojama skirtinga terminija, tad sąvokas „intervalo ilgis“ ir „intervalo plotis“ laikysime sinonimais.
Užduotis 10.2 Išmatuota 93 studentų cholesterolio koncentracija kraujyje. Gautas vidurkis yra \(308\frac{\mu mol}{l}\).
- Koks yra cholesterolio kiekio kraujyje 99% pasikliautinasis intervalas, jeigu imties standartinis nuokrypis – \(35\frac{\mu mol}{l}\)?
- Kokio imties dydžio reikia, kad intervalo ilgis būtų \(30\frac{\mu mol}{l}\)?
- Kokio imties dydžio reikia, kad intervalo ilgis būtų \(2\) vienetais mažesnis, nei gautas (a) punkte?
10.3 Proporcijos PI
Proporcija – tai kurios nors reikšmės santykinis dažnis imtyje arba dalis generalinėje aibėje. Įprastai užrašomos kaip skaičius tarp 0 ir 1. Proporcijas prasmingiausia skaičiuoti kategoriniams/diskretiesiems kintamiesiems.
Kategoriniai kintamieji gali būti skirstomi į (\(k\) – kategorijų skaičius):
- dvireikšmius – galinčius įgyti dvi skirtingas reikšmes, pvz., gėrimas tik „šiltas“ arba „šaltas“ \((k = 2)\);
- daugiareikšmius – galinčius įgyti daugiau nei 2 skirtingas reikšmes, pvz., driežas „raudonas“, „juodas“, „geltonas“, „žalias“ \((k > 2)\).
{target="_blank"}.](https://www.stat.auckland.ac.nz/~wild/ISR-15/anim/1samp.Prop.SV_100.gif)
Pav. 10.5: Simuliacija: dvireikšmio kintamojo reikšmių proporcijos skirstinio sudarymas. Vaizduojami generalinės aibės, imties ir imties statistikos (proporcijos) skirstiniai. Pilnaviduriai taškai vaizduoja į imtį patekusius elementus. Šaltinis .
Todėl ir proporcijos skirstomos į dvireikšmių kintamųjų proporcijas (arba „binominėmis“ proporcijomis, angl. binomial proportion, pav. 10.5) ir daugiareikšmių kintamųjų proporcijas (arba „multinominėmis“ proporcijomis, angl. multinomial proportion).
Primenu, kad norint skaičiuoti PI, imtis turi būti sudaryta atsitiktinai, kitaip PI neturi prasmės. Jei pats tyrėjas parinko grupių dydžio proporcijas, tada šio poskyrio metodai netinka.
Pradedantiesiems rekomenduojama žemiau pateikta proporcijos PI pasirinkimo schema. Ši schema apima tik praktikoje dažniausiai pasitaikančius, o ne visus galimus atvejus, tad tiks ne visoms situacijoms:
- kai \(k=2\) rinkitės Wilson (Wilson 1927) arba koreguotąjį Wilson (Brown ir kt. 2001) metodą. Pastarasis tinka ir tada, kai proporcija p maža (arti 0) arba didelė (arti 1).
- kai \(k>2\) ir kai kiekvienoje grupėje bent po 6 (geriausia bent po 10) narių ir grupių skaičius ne per didelis (sakykim, \(k<10\)), rinkitės Goodman metodą (Goodman 1965). Šis metodas tinkamas daugeliui praktiškai pasitaikančių situacijų.
- kai \(k>2\), kiekvienoje grupėje daugmaž vienodas skaičius narių, rinkitės Sison-Glaz metodą (Sison ir Glaz 1995; Glaz ir Sison 1999). Metodas ypač tinka tada, kai grupėse narių mažai, o grupių labai daug. Bet jei yra bent viena pagal narių skaičių dominuojanti grupė, tada metodas duoda prastus rezultatus ir jo reiktų nesirinkti.
Dvireikšmio kintamojo proporcijos PI skaičiavimams Wilson metodą rekomenduoja (Agresti ir Coull 1998) bei (Brown ir kt. 2001).
10.4 Savirankos metodai
Savirankos (angl. statistical bootstrap) metodai (Efron 1979; Efron 1987) – tai grąžintiniu imties sudarymo būdu su pakartojimu pagrįsti metodai. Palyginus su klasikiniais, savirankos metodai nereikalauja prielaidos, kad pradiniai duomenys skirstytųsi pagal kokį nors (pvz., normalųjį) skirstinį. Tačiau imties dydis kiekviename pogrupyje privalo būti pakankamai didelis (virš 20, kai kurie autoriai teigia, kad virš 50), kad gautume patikimus rezultatus.
Metodų esmę nusako citata iš vadovėlio (Čekanavičius ir Murauskas 2014, p.135):
„Savirankos idėją galima nusakyti taip: į imtį pažvelkime, kaip į mini populiaciją. Daug kartų iš jos atrinkę mini imtis, turėtume gauti objektyvesnius […] įverčius. […] Savirankos metodas reikalauja daug labai intensyvių skaičiavimų, nes pats procesas yra iteracinis. […] Nereikia nustebti, kad pritaikius tą pačią saviranką tiems patiems duomenims, gauname truputį kitokius rezultatus. Juk tos naujosios mini imtys yra atsitiktinės. Mes tik nurodome jų skaičių (vadinamąjį replikacijų skaičių).“
Vykdant saviranką, duomenys pakartotinai imami ne iš GA, o iš imties.
Idėją iliustruoja pav. 10.6.
{target="_blank"}.](https://www.stat.auckland.ac.nz/~wild/ISR-15/anim/BS_cf_Samp_Mean-SNIPPET_50.gif)
Pav. 10.6: Simuliacija: statistikos skirstinio sudarymas keliais metodais. Iš vienos reprezentatyvios imties pakartotinės atrankos (šiuo atveju, savirankos) metodu sudarytas vidurkių skirstinys kairėje (bootstrap distribution) pagal savo formą yra analogiškas iš daugelio imčių duomenų sudarytam vidurkių skirstiniui dešinėje (sampling distribution). Juodi pilnaviduriai taškai vaizduoja į imtį patekusius elementus. Šaltinis .
10.4.1 Savirankos metodai ir imties dydis
Savirankos metodai tinka ir mažoms imtims. Visgi, imties dydis turėtų būti pakankamai didelis, pvz., 20 ar daugiau tiriamųjų/stebėjimų kiekviename pogrupyje, kuriam skaičiuojamas PI. Kitu atveju gali būti gauti klaidingi rezultatai (įprastai pernelyg siauras intervalas) dėl mažo imties dydžio ir nepakankamai reprezentatyvios imties. Jei jūsų imtis itin maža, siūlau temą apie savirankos metodą ir imties dydį panagrinėti išsamiau.
Naudojant savirankos metodą, kiekviename pogrupyje privalo būti bent 20 (bent 50) taškų.
Jei imties dydis bus per mažas, gausime nepagrįstai siaurus intervalus.
10.4.2 Baziniai principai
I etapas. Iš turimos duomenų imties (o ne visos generalinės aibės, GA) pakartotinai imame imtis grąžintiniu imties sudarymo būdu – vykdome pakartotinę atranką (pakartotinai atrenkame, t.y., sudarome, imtis). Jas vadinkime pakartotinėmis imtimis (angl. resamples). Stabiliam rezultatui pasiekti įprastai reikia \(10^3\)-\(10^4\) tokių imčių. Kiekvienos jų dydis toks, kaip pradinės imties (\(n\)).
Savirankos metodui įprastai reikia 1 000 – 10 000 perskaičiavimų.
II etapas. Kiekvienai pakartotinei imčiai apskaičiuojame mus dominančios statistikos (pvz., vidurkio) įvertį: kiek yra imčių, tiek bus ir vidurkio įverčių, kurie šiek tiek tarpusavyje skiriasi. Tad sudaromas statistikų skirstinys (pav. 10.7). Šiame etape reiktų įvertinti, ar skirstinys yra normalusis, ar simetriškas, ir pagal tai pasirinkti tolimesnius analizės metodus.
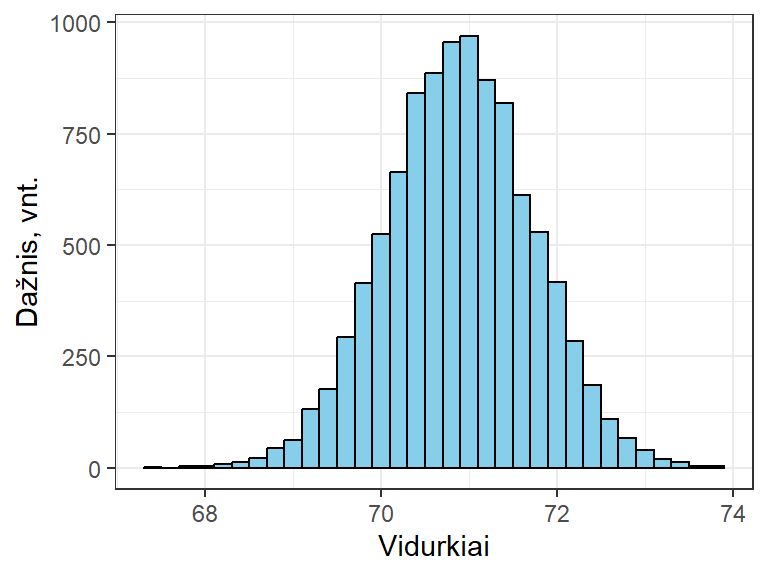
Pav. 10.7: Savirankos metodu apskaičiuotų tūkstančio vidurkių skirstinys (pavyzdys).
III etapas Pagal statistikų skirstinį apskaičiuojamos PI ribos. Tam gali būti naudojami keli metodai. Panagrinėkime du:
- Procentilių metodą.
- Koreguotąjį procentilių metodą \((BC_a)\).
Jei skirstinys yra normalusis ir žinome, kad statistika yra nepaslinktoji (pvz., vidurkis), galime naudoti patį paprasčiausią – procentilių metodą. Tiesiog apskaičiuojame skirstinio procentilius ties 2,5% ir 97,5% (tarp jų kaip tik telpa 95%) – tai ir bus PI ribos.
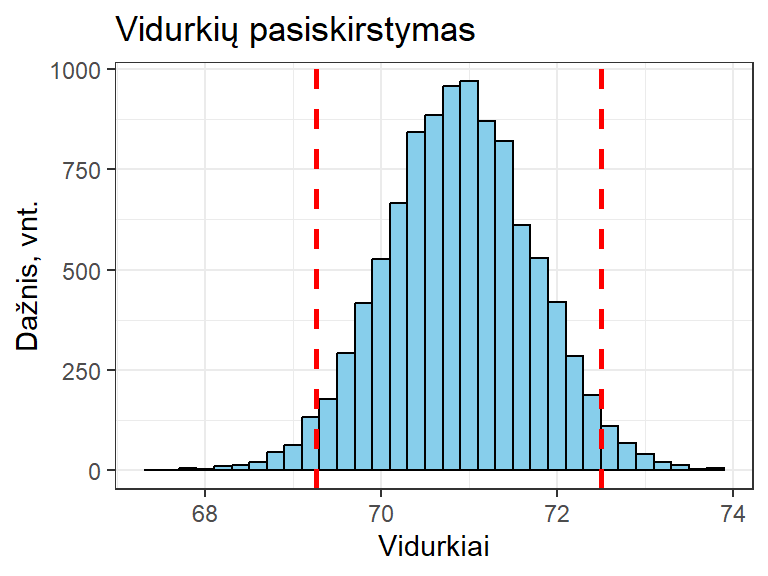
Pav. 10.8: Procentilių metodu įvertintos PI ribos (punktyrinės linijos).
Visgi, statistikų skirstinys ne visada yra normalusis, o statistikos gali būti paslinktosios. Tad sprendžiant nemažą dalį statistikos uždavinių, koreguotasis procentilių metodas \(BC_a\) (angl. bias corrected and accelerated) (Efron 1987) laikomas vienu tiksliausių PI įvertinimui, nes atsižvelgia į netikslumus, kylančius dėl statistikos paslinktumo (angl. bias) ir skirstinio asimetrijos (acceleration). Tad šį metodą rekomenduočiau rinktis kaip pagrindinį. Visgi jo trūkumas yra tas, kad skaičiavimai gali trukti šiek tiek (ar net ženkliai) ilgiau nei taikant procentilių metodą.
Reiktų prisiminti, kad bet kokį statistinį įrankį naudojant „aklai“ ir iki galo nesuprantant, ką jis daro, galima pridaryti klaidų.
10.4.3 Rekomenduojami informacijos šaltiniai
Daugiau teorinės medžiagos apie savirankos metodus galite rasti šiuose šaltiniuose:
- „Bootstrap Methods and Permutation Tests“ (Hesterberg ir kt. 2017);
- Savirankos būdu apskaičiuoti PI (Brightwell ir Dransfield 2013):
- principai ;
- kaip atlikti? (R programos kodai, demonstruojantys skaičiavimo principus);
- tinkamas ir netinkamas taikymas .
10.5 Rezultatų pateikimas
Pateikiant rezultatus reikia:
- Aprašyti metodus
- Nurodyti gautus rezultatus
10.5.1 Metodų aprašymo gairės
Aprašant PI rezultatus pateikiamos abi intervalo ribos, pasikliovimo lygmuo, tiksliai nurodomas naudotas metodas bei kompiuterinė programa bei jos priedai, kuriais atlikti skaičiavimai, ir tikslios jų versijos. Įprastai (bet ne visada) pateikiamas taškinis įvertis. Metodikos dalyje galima nurodyti skaičiavimo formulę. Taip pat svarbu nurodyti informacijos šaltinį, kuris aprašo metodą (ypač proporcijų PI skaičiavimo atveju, nes galimų metodų yra daug). Įprastai rezultatai pateikiami arba tik grafiškai, arba tik tekste.
10.5.2 Rezultatų pateikimo pavyzdžiai
Aprašymas tekste rezultatų dalyje gali atrodyti taip:
„… ilgio vidurkis yra 3 cm (95% PI 2,54–3,46) …“ arba
„… 95% PI [2,54; 3,46] …“, arba (anglų kalba)
„… 95% CI [2.54, 3.46] …“.
Tik būtina paaiškinti, kad „PI“ yra pasikliautinasis intervalas (angl. CI – confidence interval). Pasikliautinuosius intervalus galima pateikti ir lentele ar grafiku.
Savirankos būdu skaičiuotų PI aprašymo pavyzdys.
Metodikos dalyje: „Pasikliautinieji intervalai skaičiuoti savirankos metodu sudarant 3000 replikacijų ir intervalų ribas įvertinant koreguotuoju procentilių metodu \(BC_a\) (Efron 1987). Skaičiavimams naudotas programos R (versija 4.3.3) paketas boot (versija 1.3.30).“
Rezultatų dalyje: „Tarp kintamųjų nustatyta vidutinio stiprumo koreliacija (Kendall \(\tau\) = 0,57 95% PI [0,52; 0,62]).“ Pastaba: apie koreliacinę analizę rašoma skyriuje „20 Koreliacinė analizė: ryšys tarp kintamųjų.“
10.5.3 PI braižymas
Pradėkime nuo to, kad statistinio grafiko paskirtis – tiksliai, aiškiai ir suprantamai perteikti informaciją.
Skaitinius (kiekybinius) kintamuosius apibendrinančias statistikas (vidurkį, medianą ir pan.) stulpeliais vaizduoti nėra korektiška, nes stulpeliai gali iškreipti duomenų suvokimą. Taip yra todėl, kad įprastai stulpeliai braižomi nuo grafiko apačios (dažnai nuo 0 ribos) iki vidurkio (ar kitos statistikos), o viršuje paliekama tuščia erdvė. Taip susidaro įspūdis, kad apatinė grafiko dalis yra svarbesnė, nes pats stulpelio buvimas ją per daug akcentuoja. Atkreipkite dėmesį į tai, kad pačioje apatinėje šios srities dalyje duomenų gali ir nebūti (pvz., pav. 10.9 A ir B: žemiau ribos lygios 100 gramų taškų apskritai nėra, bet stulpelio dalis ten atvaizduota). Tuo tarpu gali susidaryti įspūdis, kad srityje virš vidurkio duomenų nėra (pvz., pav. 10.9 grupės G-1 reikšmės viršija 400, tačiau grafike B ties 400 yra tuštuma). Tad šiuo atveju informacija perteikta nepakankamai tiksliai.
Efektyvesnis būdas – rezultatus atvaizduoti taškais (pav. 10.9 C). Tada perdėtų akcentų nesuteikiama nei sričiai virš, nei sričiai žemiau vidurkio.
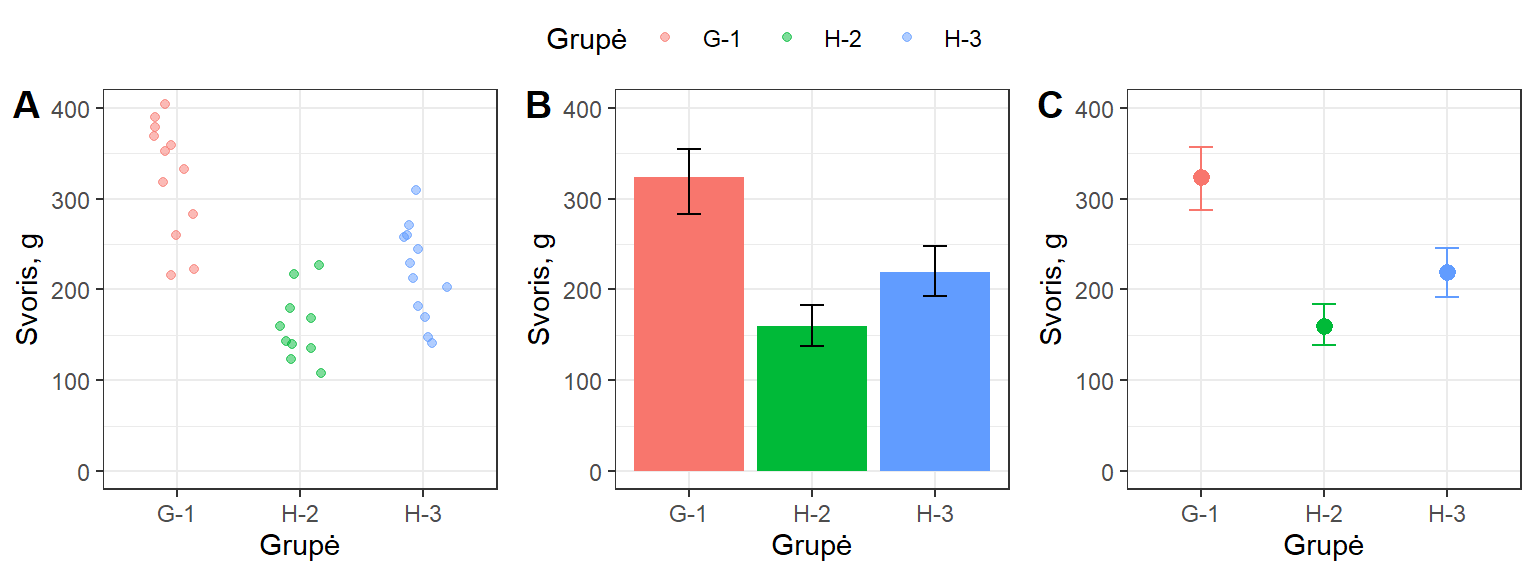
Pav. 10.9: Duomenys ir jų vidurkiai su pasikliautinaisiais intervalais (PI). A – Duomenys atvaizduoti taškais. B – Vidurkiai atvaizduoti stulpeliais (nerekomenduojama). C – Vidurkiai atvaizduoti taškais.
Vidurkius ar medianas stulpeliu vaizduoti nerekomenduojama.
Vidurkiams bei medianoms geriau rinktis tašką.
Proporcija apibūdina kategorinius (ar diskrečiuosius) kintamuosius. Tad šią aprašomąją statistiką vaizduoti stulpeliu yra prasminga ir korektiška (pav. 10.10).
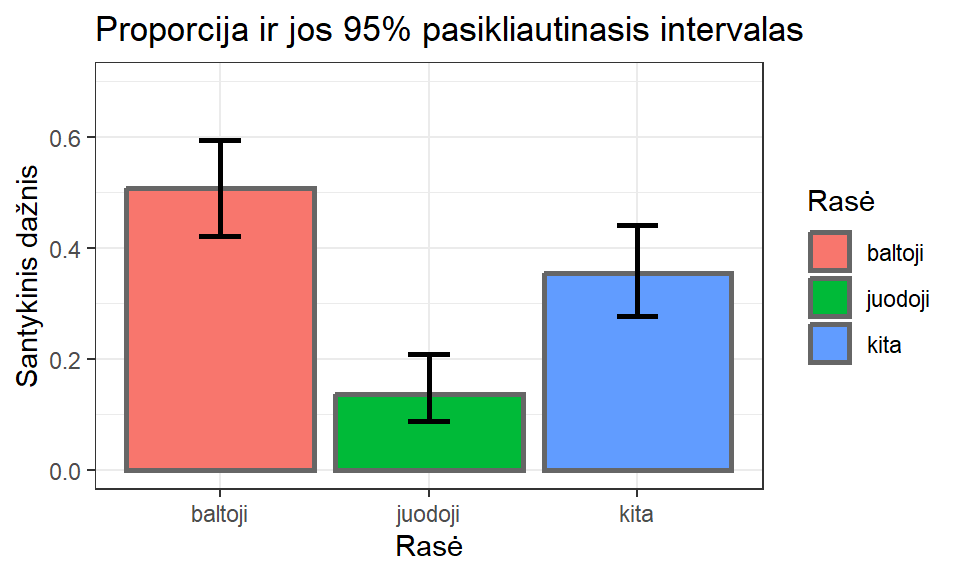
Pav. 10.10: Proporcijos ir jų pasikliautinieji intervalai.
Proporcijas vaizduoti stulpeliu yra korektiška.